Beijing Engineering Research Center for Mixed Reality and Advanced Display, School of Optoelectronics, Beijing Institute of Technology, Beijing 100081, China
Two different methods from graphic processing unit (GPU) and central processing unit (CPU) are proposed to suitably optimize look-up table algorithms of computer generated holography (CGH). The numerical simulations and experimental results show that we can reconstruct a good quality object. The computation of CGH for a three-dimensional (3D) dynamic holographic display can also be sped up by programming with our proposed method. It can optimize both file loading and the inline calculation process. The phase-only CGH with gigabyte data for reconstructing 10 MB object samplings is generated. In addition, the proposed method effectively reduced time costs of loading and writing offline tables on a CPU. It is believed the proposed method can provide high speed and huge data CGH for 3D dynamic holographic displays in the near future.
Holographic display is the most promising technology among display techniques. With the development of holography, achievements have been made in different aspects. Elimination of a zero-order beam[1,2], handling of occlusion issues[3], increasedviewing angle[4], etc. have made great contributions to three-dimensional (3D) holographic display. However, the low speed of holographic calculation is still a bottleneck for holographic display, which hinders the real-time reconstruction of 3D objects.
To solve the problem, there have been many different methods to accelerate the generation of a real-time hologram during the past few decades. Integral photography has been used in a capture and reconstruction system that can reconstruct a 3D live scene generated by fast Fourier transform (FFT) at 12 frames/s[5]. The ray-tracing approach[6] is a basic computer generated hologram (CGH) computation method. 3D objects are discretized into the point cloud, and every point of this cloud is considered a point light source. A hologram can be calculated by the sum interference fringes of each point. We can reconstruct quite high quality 3D objects in this way after a very long calculation time. Some of the calculation steps can be transferred to the offline process, which can reduce computational work inline and leads to the use of the look-up table (LUT) method[7], a data structure that stores pre-calculated results. Using it to trade space for time can optimize the hologram generation speed of the coherent ray trace (CRT) method. Because of the rise of this idea, some new methods have been proposed. A split look-up table (S-LUT) algorithm[8] splits the LUTs into horizontal and vertical vectors by using the Fresnel approximation, but its offline tables grow fast with increasing hologram size. Furthermore, a compressed look-up table (C-LUT)[9] splits the modulation factor using Fraunhofer diffraction to compress the offline table. It is a fast and memory reduced method and suitable for calculating large size holograms with limited store space, but the reconstructed object from the C-LUT algorithm cannot reach expected quality.
Except for the algorithms mentioned above, there are some optimized methods that utilize the characteristics of programming languages or high performance hardware devices. In recent years, mixed programming has been proposed that accelerates the generation speed of CGH[10]. Although combining the advantages of different programming languages is a good idea, some researchers are concerned more about high performance computing hardware[11,12]. Advanced computing hardware contributes much to high speed calculation. Graphic processing units (GPUs), as the special chip for bulk data handling, have been designed properly for numerical computation. A GPU’s parallel architecture makes it much more effective than a central processing unit (CPU), and a GPU gives a superb performance in the processing of floating type data[13]. The special mechanisms of the GPU can be used to compute a large-pixel-count hologram[14]. Currently, the GPU is used commonly to improve the computation speed of a data independent algorithm. As GPU computation performance improves, the size of the hologram increases. Most recently, a pixel hologram can be generated using an FFT-based method[15]. These algorithms can be accelerated in this way, but the coding process is complex, and data communication speed is not ideal for realizing dynamic 3D holographic display.
Sign up for Chinese Optics Letters TOC. Get the latest issue of Chinese Optics Letters delivered right to you!Sign up now
In this Letter, we propose two effective ways to accelerate the computation algorithm of a CGH based on the attributes of high performance computation hardware, GPU and CPU. We use dynamic parallelism[16–18] and file mapping techniques[19] based on the characteristics of high performance computing devices to implement two different LUT methods. The size of hologram that can be calculated has increased to 1 Gbyte with our method. We can complete the whole computation job in about 120 s, and the reconstructed 3D image quality is good enough for the human eye. Multiple GPUs are put into use as foundational hardware facilities, and one CPU is responsible for logical controlling. We use the compute unified device architecture (CUDA) as a programming platform promoted by NVIDIA. Moreover, we improve the loading speed of offline tables on the CPU by using the file mapping technique.
In order to increase the speed of the CRT method, the LUT method stores whole offline computation results. Computation devices have to load tables into computer’s memory when generating a hologram inline. The S-LUT algorithm using Fresnel approximation has decreased the inline computation load without sacrificing the quality of the reconstructed image. It splits the horizontal light modulation factor and vertical light modulation factor Both are computed offline. The inline algorithm of S-LUT is separated into two steps: In these equations, is the distance between the object plane and the hologram. represents the point location on the hologram plane. is the object point coordinate, and is the coordinate of every slice of the object. and are modulation vectors that consist of vertical and horizontal light modulation factors, respectively.
S-LUT is a fast and useful algorithm to generate a hologram in a proper size. Its consumption of storage space increases quickly with increasing hologram size. The offline tables cannot even be stored in video memory at one time when we want to compute a huge size hologram. C-LUT can preferably solve this problem. Compared with S-LUT, C-LUT takes advantage of the Fraunhofer diffraction to achieve the further approximation. Based on this, it defines the light modulation factor Because of it, there are some changes to the and factor C-LUT can save offline storage into one slice so that it is possible to generate a much larger hologram with less memory. It also takes much less time to load the offline files. The same as S-LUT’s, C-LUT’s inline process has two steps: where represents the number of slices on the axis, and is a matrix.
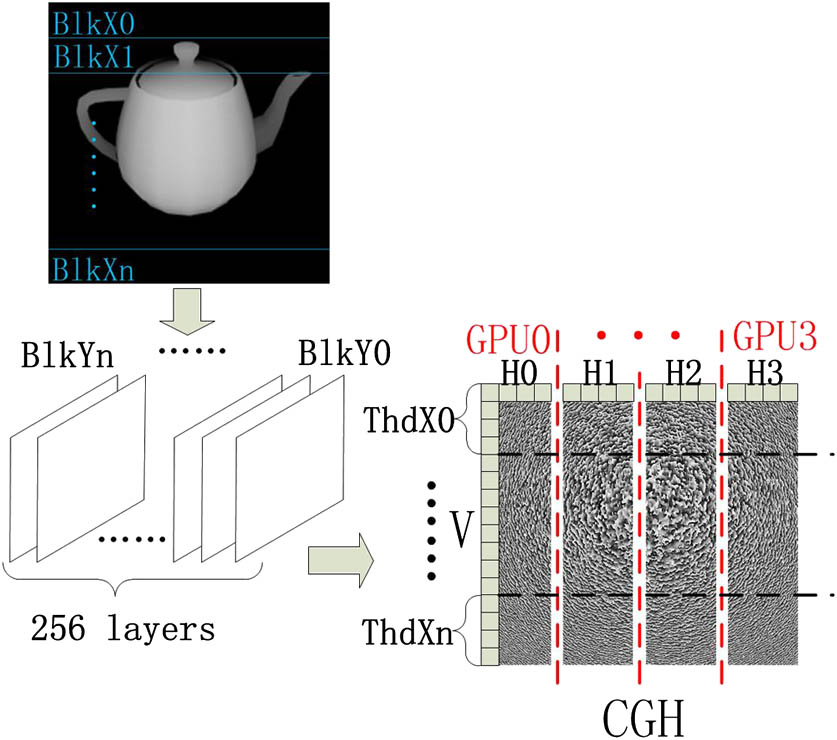
CUDA is a general parallel computing architecture that can implement the complex and time-consuming computation efficiently and can appropriately support the highly parallel structure of the LUT algorithm. The newest version of CUDA provides a characteristic called dynamic parallelism, which can accommodate the size of blocks and threads in terms of the computation complexity. This new property makes the nested programming much simpler than before and can accelerate the LUT method to some extent. It has been used extensively in many other fields. This technique allows GPU to make a judgment of the results of the computation directly without transferring the data back to the CPU. Obviously, dynamic parallelism can reduce the time spent on the data communication between the GPU and CPU. Based on this mechanism, the computing process is shown in Fig. 1.
Figure 1.Diagram of the generation of holograms by dynamic parallelism. “Blk” and “Thd” are the abbreviations of block and thread, respectively.
In our method, we allocate the blocks and threads as described above and implement the S-LUT and C-LUT algorithms in this way. It divides the whole hologram into pieces and optionally adjusts the calculation work to the current computing resources. Dynamic parallelism reduces the complexity of the nested program and converts it into a more controllable form. We can modify the size of every sub-hologram by barely changing the code. In order to take advantage of the dynamic parallelism mechanism of CUDA, we consider the light intensity information of each object point as a matrix and multiply it with its vector of modulation factor. Therefore, the accumulation of the light modulation factor in the same row as the object can be computed as a kind of matrix manipulation. With the change of accumulation, we can use the dynamic parallelism to split the factor into many segments and then sum up each part together concurrently. It does finish a job to accelerate accumulation procedure. The inline process flow chart is shown in Fig. 2. File mapping and the dynamic parallelism technique are used in host and device, respectively. The device is responsible for the implementation of S-LUT and C-LUT. The complex data we process consists of two single-precision data formats.
For the computation of holograms with sizes larger than based on the S-LUT algorithm, offline tables are so large for the limited video memory on GPU that the video memory has to be refreshed many times. This kind of manipulation consumes extra expenditures of time, which can be avoided by increasing video memory. The results are shown in Fig. 3.
Figure 3.Results of time consumption on (a) S-LUT and (b) C-LUT.
In Ref. [8], the author generated a hologram accumulated by over 10000 object points at resolution, which took 500 ms. We can calculate a hologram with the same object points and a size of in with the optimization of dynamic parallelism. In our experiment, the granularity level of blocks and threads also affect the speed of calculation. We modify the part of the hologram computed in a GPU into smaller sub-holograms, which means making the parallel computation have a finer level of granularity. It can improve the processing speed to some extent, but it won’t be improved all the time because of thread creation and synchronization costs.
The LUT algorithm trades storage space for inline run time overhead so whole offline tables have to be loaded before starting to compute inline. It costs us huge amounts of time when we use the file stream functions to load the offline tables of a large hologram. The inputting and outputting of the file are both very time consuming. The memory mapping file technique is a memory management method under the control of an operation system. It grants an application permission to access the files in the disk through a memory pointer. In other words, this technique establishes the connection between the whole or part of the file in the hard drive and the fixed area of the virtual address space of the process. In this way, we can access a file directly and avoid both the file stream I/O operation and file buffer. It is especially efficient for loading some huge size files. We set the process of writing and reading offline table files as a graphic example in Fig. 4.
As shown in Fig. 4, first we establish a mapping between the logic memory and the hard disk before we try to read or write the light modulation factor and offline tables on the disk. The virtual logic address expressed by the file pointer is one-to-one mapping to the physical address now. Second, when the program wants to obtain the data of the offline table files, the operation system will invoke a page fault interrupt to call for the offline holographic data because there is no related data in logic memory. Third, these data are loaded into memory and then obtained by the process. This file reading and writing mechanism avoids the regular buffer copies, so we can load the data at one time rather than reading the offline table data twice from this process with other processes in this way, which means it can support multi-process programming.
Our experiments are accomplished by a computer with the specifications shown in Table 1. Our program is running on one CPU and four GPUs. Some parameters we used are listed in Table 2.
Diffraction distance is 600 mm, and pixel size is 8 μm. Based on these parameters, we compare the time costs for different offline table processing cases. The comparison of file mapping and regular file stream techniques are shown in Figs. 5 and 6.
Figure 5.Processing time comparison of (a)reading file process and (b)writing file process on S-LUT.
To compare the relationship of hologram size and file loading time consumption, Figs. 5 and 6 show that the file mapping technique can reduce the time costs when we read or write data of offline tables from disk to the memory. With the increasing size of the hologram, the file mapping technique can keep relatively gentle and slow time expenditure. For different cases, the file processing time consumptions of S-LUT are times more than C-LUT because of the different sizes of the processing data. The average time of writing offline holographic data for the file stream method in the S-LUT case is about 14 min, which is nearly 56 times larger than the file mapping method. For the reading case of S-LUT, the time cost of the file stream is 11 min on average. Compared with it, the average cost time of file mapping is .
The numerical and optical reconstructions of are also completed by different algorithms. The simulations and optical experiments are shown in Fig. 7. We use the phase component loaded on the SLM to reconstruct the 3D object dynamically.
Figure 7.Reconstructed 3D objects with different depth by S-LUT: (a) and (c) focus on the teacup, and (b) and (d) focus on the teapot, where (a) and (b) are simulated results, and (c) and (d) are recorded in optical experiments.
Our program is flexible for different sizes and is capable of generating huge CGH without quality loss. We can generate a 1 Gbyte hologram with more than object points in about 120 s with our proposed method. The occlusion processing method in our program can speed up the calculation. The calculation precision and speed are in good agreement with the theoretical predictions. Furthermore, the dynamic parallelism technique cuts down the code complexity, which makes the program much easier to understand.
In conclusion, we propose one method to speed up the generation of CGH by GPUs and CPU based on S-LUT. Dynamic parallelism will lead to simpler programming and easier management of thread granularity. In addition, it can also reduce the inline time consumption of both LUT algorithms to some extent. The file mapping technique saves more than 100 times than file I/O stream method in average. The method can deal with huge data of up to total, which is a useful tool to realize the real-time 3D holographic display of the future. We can use part of the information of the huge hologram to reconstruct the object with a high quality by different encoding methods[20]. It could be applied to big data processing for various applications such as 3D data processing, cloud computation, etc.