
Yilin He, Yunhua Yao, Dalong Qi, Yu He, Zhengqi Huang, Pengpeng Ding, Chengzhi Jin, Chonglei Zhang, Lianzhong Deng, Kebin Shi, Zhenrong Sun, Xiaocong Yuan, Shian Zhang, "Temporal compressive super-resolution microscopy at frame rate of 1200 frames per second and spatial resolution of 100 nm," Adv. Photon. 5, 026003 (2023)
- Advanced Photonics
- Vol. 5, Issue 2, 026003 (2023)
Abstract
Keywords
1 Introduction
Exploring fine structures and their dynamics beyond the optical diffraction limit is an urgent requirement in many research fields, especially in biology and medicine. To date, various super-resolution microscopy techniques have been developed to surpass the optical diffraction limit. For example, stimulated emission depletion microscopy (STED) improved the resolution by shrinking the point spread function (PSF) with nonlinear stimulated emission depletion based on confocal microscopy.1 Single molecule localization microscopy (SMLM), involving photoactivated localization microscopy (PALM)2 and stochastic optical reconstruction microscopy (STORM),3 achieved a higher resolution by localizing a single fluorescent molecule with sparse fluorescence activation instead of recording fluorescence distribution. Structured illumination microscopy (SIM) obtained a super-resolution image by loading normally inaccessible high spatial frequency information into the recorded images by the moiré effect.4 Super-resolution optical fluctuation imaging (SOFI) utilized random temporal signal fluctuations of single emitters to achieve background-free super-resolution microscopy based on high-order statistics.5 In addition, some novel microscopy techniques are emerging by combining multiple super-resolution imaging methods. For example, a combining method with STED and SMLM realized better resolution and less fluorophore bleaching, such as minimal STED6 or minimal photon fluxes (MINFLUX).7 A STED-SIM method achieved 30 nm resolution and single-molecule sensitivity by utilizing STED to provide nonlinear modulation for SIM.8 A SIM-based point localization estimator (SIMPLE) method obtained simultaneous particle localization with twofold precision by using phase-shifted sinusoidal wave patterns as nanometric rulers.9 Super-resolution microscopy, as a powerful imaging tool, has boosted the development of biomedicine, and numerous discoveries have been reported,10 such as centrosome structure and function,11,12 nuclear and chromatin organization,13,14 and mitochondrial membrane protein organization.15
It should be noted that all the techniques mentioned above acquire the super-resolution ability at the expense of reducing the imaging speed by either point scanning or multiframe computation. Thus, the imaging speed is inevitably limited, which greatly affects the observation of high-speed dynamics of fine structures. Recently, a single-image super-resolution (SISR) technique was proposed to overcome the limited imaging speed by extracting a super-resolution image from one recorded image, which allowed the super-resolution imaging speed to reach the frame rate of a camera. Many deep-learning-based algorithms with neural networks have accelerated the development of SISR due to their outstanding image processing ability. For example, Wang et al.16 employed a generative adversarial network (GAN) to realize cross-modality super-resolution from confocal microscopy images to STED images or from total internal reflection fluorescence (TIRF) images to SIM images. Chen et al.17 proposed a novel network combining a super-resolution network and a signal-enhancement network to transfer wide-field images to SMLM images. Qiao et al.18 developed a deep Fourier channel attention network (DFCAN) for super-resolution imaging by leveraging the frequency content difference across distinct features to learn precise hierarchical representations of high-frequency information in diverse biological structures. Obviously, SISR improves the super-resolution imaging speed by avoiding the point scanning and multiframe computation, but the imaging speed is still restricted by the frame rate of a camera.
To further improve the super-resolution imaging speed that breaks through the frame rate limit of a camera, we propose and demonstrate a novel temporal compressive super-resolution microscopy technique, termed TCSRM, which combines an enhanced temporal compressive microscopy and a deep-learning-based image reconstruction. Here, the purpose of the enhanced temporal compressive microscopy is to improve the imaging speed by reconstructing multiple images from one compressed image, and the deep-learning-based image reconstruction seeks to achieve the super-resolution without reduction in the imaging speed. The high-speed super-resolution imaging ability of TCSRM is verified in theory and experiment, and the experimental result shows that TCSRM has the imaging capability with a frame rate of 1200 frames per second (fps) and spatial resolution of 100 nm based on a 200 fps CMOS and a
Sign up for Advanced Photonics TOC. Get the latest issue of Advanced Photonics delivered right to you!Sign up now
2 Theoretical Model
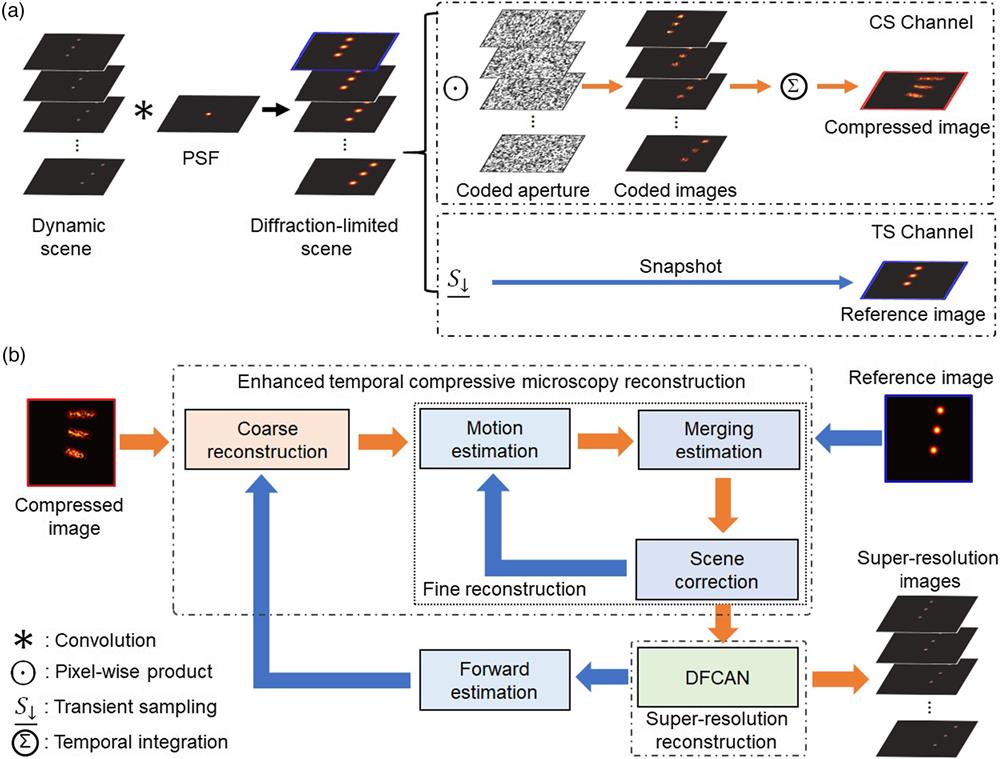
As an inherent feature, natural dynamic scenes have sparsity in some transform domains. Thus, the spatiotemporal information of a dynamic scene can be recovered from a compressed sampling based on compressive sensing theory.19,20 Moreover, the spatial distributions at adjacent moments have continuity. Therefore, the spatial distribution at a moment can provide the reference information for the dynamic scene.21,22 Based on these premises, we propose an enhanced temporal compressive microscopy to capture the high-speed dynamic scene, which combines the spatiotemporal compressive information and the transient spatial information. The imaging model is shown in Fig. 1(a). The original dynamic scene
![]()
Figure 1.Theoretical model of TCSRM. (a) Image acquisition flowchart of TCSRM. (b) Image reconstruction framework of TCSRM.
The image reconstruction framework of TCSRM is shown in Fig. 1(b). The compressed image in the CS channel is first recovered to a diffraction-limited dynamic scene
Here, the error will be calculated in each iteration. Once the error reaches the preset threshold, the desired super-resolution dynamic scene is obtained. It is worth mentioning that TCSRM is rather different from the simple concatenation of temporal compressive imaging and DFCAN. The recovered images from temporal compressive imaging have different features compared with natural images, which is due to the information loss during compressive acquirement and the imperfect optimization during image reconstruction. Moreover, the DFCAN is trained by using natural image pairs with low and high resolution. The mismatch in image features makes it difficult to obtain acceptable results because of the generalization problem in end-to-end networks. However, TCSRM utilizes the additional reference frame to recover the images with higher accuracy, which decreases the mismatch in image features between recovered images and natural images. In addition, the global iterations of compressive image reconstruction and super-resolution processing are conducted in TCSRM to optimize the final super-resolution images with corresponding forward estimation. In this way, the super-resolution ability of DFCAN can be fully utilized, alleviating the generalization problem.
3 Simulation Result
In order to verify the feasibility of TCSRM, we design a dynamic scene with high-speed moving nanorings for simulation. In the simulation, the diameter of the rings is 750 nm, and the width of the rings (full width at half-maximum, FWHM) is 96 nm. The three nanorings move in different ways. The top one moves right with a constant velocity of
![]()
Figure 2.Simulation result of moving nanorings by TCSRM. (a) Compressed image and reference image measured by two channels in TCSRM. (b) GT and TCSRM images for six consecutive frames. The moving trajectories of the nanorings are labeled with green lines. (c) Motion traces of the three nanorings in the whole scene from GT (lines) and reconstructed result by TCSRM (circles, squares, and rhombuses). (d) Radial intensity distributions of the nanorings along the white line in the reference, GT, and TCSRM images (
4 Experimental Design
The experimental arrangement of TCSRM is shown in Fig. 3. A continuous-wave laser with the wavelength of 532 nm (Laser Quantum, Torus 532) is used as the excitation source. The laser beam is expanded by a beam expander and reflected by a dichroic mirror and is then focused in the microchannel of a customized glass microfluidic chip on the sample stage with an objective lens (Olympus, UPlanApo, Oil, 100×, NA 1.5). The depth and width of the microchannel are 10 and
![]()
Figure 3.Experimental design of TCSRM. BE: beam expander; L: lens; DM: dichromatic mirror; OL: objective lens; DMD: digital micromirror device.
5 Experimental Result
The experimental result of a flowing fluorescent bead in a microfluidic chip is shown in Fig. 4, and the whole video is provided in Video 2. One selected compressed image and corresponding reference image are given in Fig. 4(a), and the reconstructed six images by TCSRM are shown in Fig. 4(b). The size of the bead in TCSRM is obviously decreased compared with that in the reference image, and the moving trajectory can be clearly distinguished. To show the resolution improvement, the intensity distributions of the bead along the horizontal and vertical directions in the reference image and the first frame of TCSRM images are extracted and given in Figs. 4(c) and 4(d). The sizes of the bead (FWHM) in the horizontal and vertical directions for the reference image are 264 and 237 nm, and those in the TCSRM image are 118 and 93 nm, respectively. Thus, the resolution is improved by a factor of about 2.2. That is to say, TCSRM has the high-speed super-resolution ability with the frame rate of 1200 fps and the spatial resolution of about 100 nm, which surpasses conventional microscopy. The difference in the sizes in the two directions is due to the high-speed moving of the bead in the horizontal direction, which results in the stretch of the bead in this direction during the image reconstruction. According to the measurement of TCSRM, the average speed of the bead is about
![]()
Figure 4.Experimental result of flowing fluorescent bead in microchannel by TCSRM. (a) Compressed and reference images recorded by two cameras. (b) Reconstructed images by TCSRM. The trajectory of the moving bead is marked with white dashed lines. (c) and (d) Intensity distributions of the fluorescent bead along the horizontal and vertical directions in the reference image and the first frame in TCSRM images (
6 Discussion and Conclusion
TCSRM is a lossy imaging by spatial encoding, which will reduce the image quality. One way is to improve the sampling rate in hardware, such as multiple CS channels, and the other way is to develop a more advanced image reconstruction algorithm in software, such as hybrid super-resolution algorithm. The reference image in the TS channel provides detailed spatial information for the image reconstruction in the CS channel, and therefore the exposure time of CMOS2 should be as short as possible under the condition of ensuring high enough signal-to-noise ratio. In general, the maximum exposure time should be shorter than the division of the exposure time of CMOS1 and the compressive ratio. Additionally, in order to obtain the effect of the super-resolution, the data compression ratio in the CS channel cannot be too large, and the value of around 10 is appropriate. An important application of TCSRM is biomedical imaging. Compared with other wide-field super-resolution imaging, such as SIM and SISR, TCSRM has lower light flux due to two-channel sampling, and the light field in the CS channel is spatially modulated in amplitude, while that in the TS channel is partially detected in a very short time scale. An end-to-end deep-learning super-resolution algorithm is utilized in TCSRM, which has the limitation in generalization. Transfer learning31 can be used to reduce the required training datasets. Meanwhile, self-supervised networks, such as GAN32 and deep image prior,33 may be adopted to improve the generalization of TCSRM.
In conclusion, we have developed a high-speed super-resolution microscopy technique TCSRM by combining an enhanced temporal compressive microscopy and a deep-learning-based image reconstruction. The enhanced temporal compressive microscopy realizes the high-speed imaging and the deep-learning-based image reconstruction obtains the resolution beyond the optical diffraction limit. Both the theoretical and experimental results verify the high-speed super-resolution imaging ability of TCSRM, and the imaging performance with a frame rate of 1200 fps and spatial resolution of 100 nm is experimentally obtained. TCSRM provides a powerful tool for the observation of high-speed dynamics of fine structures, especially in hydromechanics and biomedical fields, such as microflow velocity measurement,34 organelle interactions,35 intracellular transports,36 and neural dynamics.37 In addition, the framework of TCSRM can also offer guidance for achieving higher imaging speed and spatial resolution in holography,38 coherent diffraction imaging,39 and fringe projection profilometry.40
Yilin He is a PhD student at State Key Laboratory of Precision Spectroscopy, East China Normal University under the supervisions of Prof. Shian Zhang. His research focuses on high-speed super-resolution microscopy.
Yunhua Yao is an associate professor at State Key Laboratory of Precision Spectroscopy, East China Normal University (ECNU). He received his PhD in optics from ECNU in 2018. His current research interest focuses on high-speed super-resolution microscopy and ultrafast optical imaging.
Dalong Qi is a young professor at State Key Laboratory of Precision Spectroscopy, East China Normal University (ECNU). He received his PhD in optics from ECNU in 2017. His current research interest focuses on ultrafast optical and electronic imaging techniques and their applications.
Yu He is a PhD student at State Key Laboratory of Precision Spectroscopy, East China Normal University under the supervisions of Prof. Shian Zhang. His research focuses on high-speed super-resolution microscopy.
Zhengqi Huang is a PhD student at State Key Laboratory of Precision Spectroscopy, East China Normal University under the supervisions of Prof. Shian Zhang. His research focuses on high-speed super-resolution microscopy.
Pengpeng Ding is a PhD student at State Key Laboratory of Precision Spectroscopy, East China Normal University under the supervisions of Prof. Shian Zhang. His research focuses on ultrafast optical imaging.
Chengzhi Jin is a PhD student at State Key Laboratory of Precision Spectroscopy, East China Normal University under the supervisions of Prof. Shian Zhang. His research focuses on ultrafast optical imaging.
Chonglei Zhang is a professor from Nanophotonics Research Center, Shenzhen University. He received his PhD in physics from Nankai University in 2007. His current research interest focuses on super-resolution microscopy and surface plasmon resonance.
Lianzhong Deng is an associate professor from State Key Laboratory of Precision Spectroscopy, East China Normal University (ECNU). He received his PhD in optics from ECNU in 2008. His current research interest focuses on ultrafast optical and electronic imaging techniques and their applications.
Kebin Shi is a professor from State Key Laboratory for Mesoscopic Physics, Peking University. He received his PhD from Pennsylvania State University. His current research interest focuses on nonlinear photonics and biomedical imaging.
Zhenrong Sun is a professor of the State Key Laboratory of Precision Spectroscopy, East China Normal University (ECNU). He received his PhD in physics from ECNU in 2007. His current research interest focuses on ultrafast dynamics of clusters and ultrafast optical imaging.
Xiaocong Yuan is a professor and the director of Nanophotonics Research Center, Shenzhen University. He received his PhD in physics from King’s College London in 1994. His current research interest focuses on optical manipulation, high-sensitivity sensor, super-resolution microscopy, and surface-enhanced Raman spectroscopy.
Shian Zhang is a professor and the deputy director of State Key Laboratory of Precision Spectroscopy, East China Normal University (ECNU). He received his PhD in optics from ECNU in 2006. His current research interest focuses on ultrafast optical imaging, high-speed super-resolution microscopy, and light field manipulation.
References
[17] R. Chen et al. Deep-learning super-resolution microscopy reveals nanometer-scale intracellular dynamics at the millisecond temporal resolution(2021).
[28] J.-Y. Bouguet. Pyramidal implementation of the affine Lucas Kanade feature tracker description of the algorithm. Intel Corp., 5, 1-10(2001).
[31] F. Z. Zhuang et al. A comprehensive survey on transfer learning. Proc. IEEE, 109, 43-76(2021).
[33] D. Ulyanov et al. Deep image prior, 9446-9454(2018).
[36] R. D. Vale. The molecular motor toolbox for intracellular transport. Cell, 112, 467-480(2003).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20