1State Key Laboratory of Precision Spectroscopy, School of Physics and Electronic Science, East China Normal University, Shanghai 200062, China
2Department of Electrical and Computer Engineering, University of Illinois at Urbana-Champaign, Urbana, Illinois 61801, USA
3Institut National de la Recherche Scientifique, Centre Énergie Matériaux Télécommunications, Laboratory of Applied Computational Imaging, Varennes, Québec J3X1S2, Canada
4Collaborative Innovation Center of Extreme Optics, Shanxi University, Taiyuan 030006, China
5Collaborative Innovation Center of Light Manipulations and Applications, Shandong Normal University, Jinan 250358, China
Compressed ultrafast photography (CUP) is the fastest single-shot passive ultrafast optical imaging technique, which has shown to be a powerful tool in recording self-luminous or non-repeatable ultrafast phenomena. However, the low fidelity of image reconstruction based on the conventional augmented-Lagrangian (AL) and two-step iterative shrinkage/thresholding (TwIST) algorithms greatly prevents practical applications of CUP, especially for those ultrafast phenomena that need high spatial resolution. Here, we develop a novel AL and deep-learning (DL) hybrid (i.e., ) algorithm to realize high-fidelity image reconstruction for CUP. The algorithm not only optimizes the sparse domain and relevant iteration parameters via learning the dataset but also simplifies the mathematical architecture, so it greatly improves the image reconstruction accuracy. Our theoretical simulation and experimental results validate the superior performance of the algorithm in image fidelity over conventional AL and TwIST algorithms, where the peak signal-to-noise ratio and structural similarity index can be increased at least by 4 dB (9 dB) and 0.1 (0.05) for a complex (simple) dynamic scene, respectively. This study can promote the applications of CUP in related fields, and it will also enable a new strategy for recovering high-dimensional signals from low-dimensional detection.
1. INTRODUCTION
Ultrafast imaging has played an indispensable role in photochemistry [1,2], biomedicine [3–5], microfluidics [6], shock waves [7], and plasma physics [8]. Recently, various ultrafast imaging techniques have been developed, including compressed ultrafast photography (CUP) [9–11]. Unlike some active ultrafast imaging techniques that need specific illumination light [12–14] or a pump–probe technique that requires multiple measurements [15–17], CUP is a single-shot and passive ultrafast imaging technique. Its temporal resolution and number of frames can reach tens of femtoseconds and several hundred, respectively. Therefore, CUP has great advantages for measuring some self-luminous or non-repeatable ultrafast phenomena, which is attributed mainly to the novel model of CUP, which combines compressed sensing (CS) theory and time–space conversion technology. So far, CUP has been successfully applied to measure light reflection and refraction [9], femtosecond temporal focusing [10], photonic Mach cones [18], dissipative solitons [19], phase-sensitive transparent objects [20], three-dimensional (3D) objects [21], ultrashort laser spatiotemporal evolution [22], and photoluminescence processes [9]. However, due to the high data compression ratio, the fidelity of reconstructed images for CUP is relatively low by the conventional two-step iterative shrinkage/thresholding (TwIST) algorithm, which limits its practicality. To improve image fidelity, a variety of methods have been proposed, such as a space- and intensity-constrained image reconstruction algorithm [23], augmented-Lagrangian (AL)-based image reconstruction algorithm [24], plug-and-play alternating direction method of multipliers algorithm [25], optimizing the codes for CUP [26], lossless CUP [18], and multi-encoding CUP [27]. These proposed schemes can improve image fidelity to a certain extent, but there are still great challenges in measuring the complex dynamic scenes.
In image reconstruction of CUP, all selections of the sparse domain, determination of relevant iteration parameters, and denoising after iteration calculation greatly limit image fidelity. To completely solve these problems, we developed a novel image reconstruction method based on an AL and deep-learning (DL) hybrid (i.e., ) algorithm. This idea is borrowed mainly from some early algorithms, such as the AL algorithm [24,28,29], learning iteration parameters [30–33], learning sparse domain [34–37], and U-net architecture [38], but there are still many differences compared to each of the early algorithms. First, the algorithm utilizes multiple learning transformations to seek the best sparse domain. Typically, the sparse domain in conventional TwIST and AL algorithms is determined before image reconstruction [24,39], so it is usually not optimal for one dynamic scene. In contrast, the sparse domain in the algorithm can be optimized in multiple transformations, which is more pertinent. Second, the algorithm takes full advantage of gradient descent (GD), DL, and AL algorithms, which simplifies the mathematical architecture to deal with the 3D tensor problem, and these advantages can reduce the cost of each iteration and decrease the number of iterations. Third, the algorithm optimizes the relevant iteration parameters by learning the dataset, which is different from previous AL and TwIST algorithms, where these parameters are artificially predetermined. Finally, the algorithm uses a U-net architecture containing attention layers to help denoise and retain the spatial details of the images after iteration calculation. Importantly, our theoretical simulation and experimental results show the algorithm can obtain much higher image fidelity than conventional AL and TwIST algorithms for CUP, which strongly supports our theory.
2. PRINCIPLE
In CUP, a 3D dynamic scene is encoded by operator , sheared by operator , and integrated by operator , and finally a two-dimensional (2D) image is obtained. For convenience, hereafter, is abbreviated to , and is abbreviated to . Mathematically, this process can be described as
For simplicity, we define . Thus, Eq. (1) can be further written as
To recover 3D from 2D , we need to solve the inverse problem of Eq. (2). The number of elements in is much larger than that in , so the inverse problem of Eq. (2) is undetermined. The CUP strategy is to introduce a CS theory [9]. The CS theory makes full use of the sparsity of in a certain domain to recover the original information. This sparsity in one domain means that only a few elements are nonzero, while most of the elements are zero. Consider a case in which has elements and has elements in the original domain, and has nonzero elements in a sparse domain, i.e., the sparsity where and . Due to the fact that is generally larger than , this makes it possible to solve the inverse problem of Eq. (2). In a practical solution, the CS algorithm minimizes in a sparse domain on condition of Eq. (1), which is shown as where is the expression of in the sparse domain. According to CS theory [40,41], the original dynamic scene can be completely recovered when where is a constant correlated with the number of elements , is the mutual coherence between the sparse basis of the sparse domain and operator , determined by operators , , and . From Eq. (4), one can see that both increasing and reducing and are feasible schemes to improve the quality of image reconstruction. However, increasing , i.e., increasing the sampling rate, will reduce the spatial resolution or requires many streak cameras, which is impractical in the actual CUP system. Thus, reducing and is the best choice. Optimizing can reduce only , while optimizing can reduce both and ; therefore, here we employ the method of optimizing . To optimize , we impose a low-rank property on the entire dynamic scene (tensor) with many different transformations [42], which is different from traditional methods with only one transformation. Thus, problem (3) can be further written as where represents one transformation in the sparse domain, and denotes the total number of transformations. In transforming problem (5) from a constraint into an unconstraint, there exist two frameworks: the penalty function method and the AL method. The performance of the AL method is better than that of the penalty function method, which has been proved in previous works [24,29], and therefore, here the AL method is adopted. Thus, problem (5) can be transformed into where and are the Lagrangian multiplier and penalty parameter, respectively, which are associated with . For convenience, problem (6) is further written as
To solve problem (7), an auxiliary variable is introduced into problem (7), and is written as
By adopting the AL method, the constrained problem (8) can be transformed into where and are the Lagrangian multipliers and penalty parameters, respectively, which are associated with in different transformations. By transformation, problem (9) can be further written as
Problem (10) can be solved by an alternating direction method of multipliers (ADMM) based on an iteration of solving the -subproblem and -subproblem alternatively. However, in the -subproblem, the sparse domains in different transformations lead to different solutions at the beginning of the iteration. Therefore, some independent auxiliary variables are introduced for each transformation, and thus problem (10) can be written as
To solve problem (11), the ADMM is also adopted to solve the -subproblem and -subproblem alternatively. In the th iteration, the -subproblem can be written as and the -subproblem can be written as
The -subproblem in Eq. (12) is a quadratic regularized least-squares problem, and its direct solution is given in a closed form as where is an identity operator. It is expensive to compute HARD due to large data, so here the GD algorithm is used to solve the -subproblem. The main shortcoming of the GD algorithm is that the number of iterations is very large because it is difficult to choose the step size. Some methods have been developed to obtain a better step size through much computation, such as the Barzilai and Borwein (BB) method [43,44]. Here, a learning method is used to seek the optimized step size. In our method, the number of iterations is much less than that of the BB method. Based on the GD algorithm, the solution to Eq. (12) can be expressed as where is the step size in the GD algorithm, and here the GD algorithm is utilized to calculate Eq. (15). From Eqs. (15) and (13), one can see that the solution to problem (6) depends mainly on instead of . For convenience, the solution to can be further written as
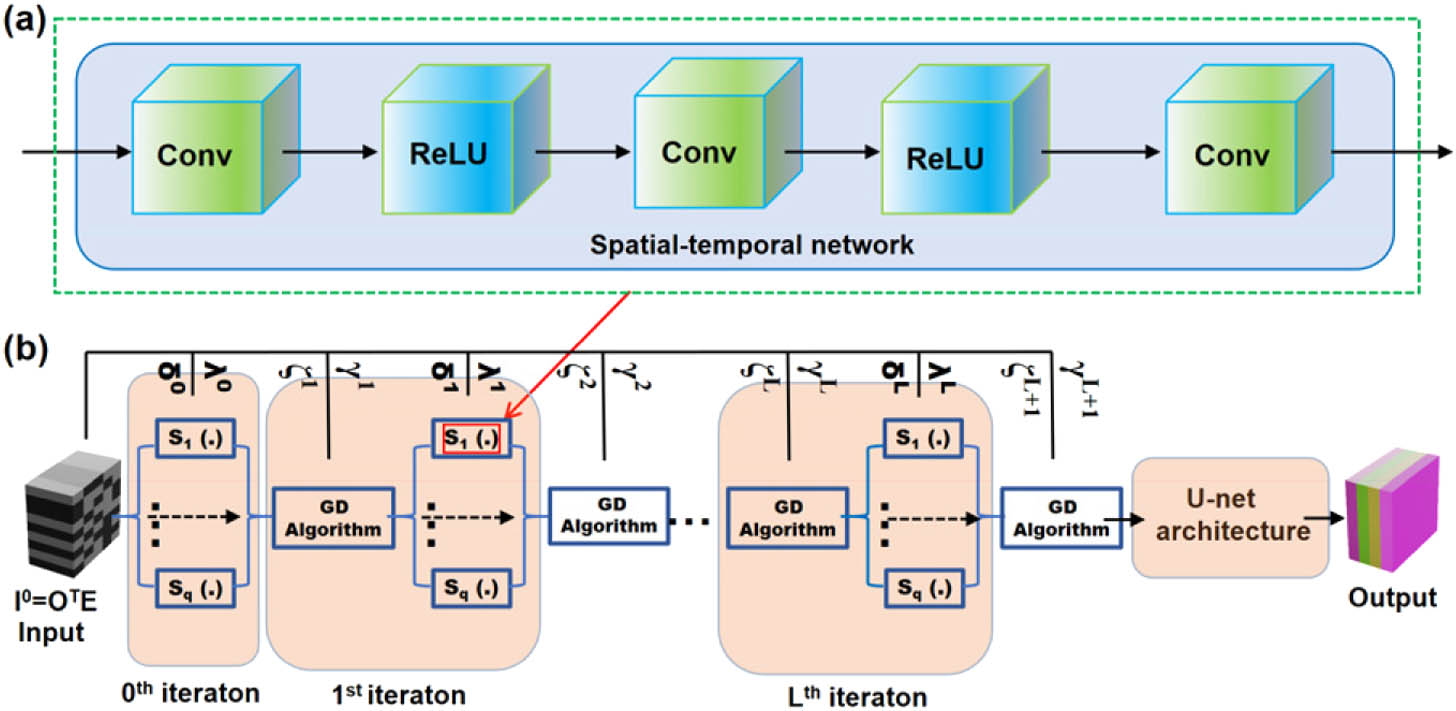
Figure 1.Data flow chart of the algorithm. (a) Solver in a sparse domain; (b) general framework by connecting each iteration in a sequence order. Here, each is calculated in parallel to producing , and GD algorithm is employed to calculate .
Figure 3.Reconstructed results of (a) boatman, (b) ocean animal, and (c) finger by the (second row), AL (third row), and TwIST (fourth row) algorithms, together with the ground truth (first row) for comparison. The last column is the enlarged image in the corresponding red squares.
Here, only three representative pictures are selected, and an interesting area in each dynamic scene is enlarged for observation. Spatial details in the boatman, ocean animal, and finger can be clearly observed by the algorithm, while these details are submerged by the AL and TwIST algorithms, which is disadvantageous for high-spatial-resolution imaging of a dynamic scene. To intuitively compare the improved efficiency in image fidelity by the algorithm, we calculate PSNR and SSIM, and the calculated results are given in Table 1. Compared to the AL and TwIST algorithms, both PSNR and SSIM by the algorithm are significantly improved. Here, PSNR (SSIM) is increased by at least 4.35 dB (0.136) for the boatman, 5.47 dB (0.114) for the ocean animal, and 9.78 dB (0.051) for the finger. Based on these calculated results, a rule can be found, which is, the simpler the spatial structure of the dynamic scene, the higher the improvement efficiency of PSNR, while the improvement efficiency of SSIM shows the opposite behavior. This phenomenon should be related to the sparsity of the dynamic scene; the simpler dynamic scene usually has higher sparsity, and vice versa. PSNR is based on a logarithmic function, which is not very well matched to perceived visual quality, but SSIM is based on visible structures in the image. Thus, PSNR has high improvement efficiency for a simple dynamic scene (i.e., finger), while SSIM has high improvement efficiency for a complex dynamic scene (i.e., boatman). In addition, the algorithm can reconstruct a dynamic scene in only a few seconds, which is much shorter than the AL and TwIST algorithms, which need tens of seconds; the computing efficiency is improved by an order of magnitude, which is very beneficial in practical applications of CUP.
Average PSNR (in dB) and SSIM by Different Image Reconstruction Algorithms in Different Dynamic Scenes
Scene
AL
TwIST
PSNR
SSIM
PSNR
SSIM
PSNR
SSIM
Boatman
28.50
0.836
24.15
0.700
22.47
0.589
Ocean animal
30.47
0.916
25.00
0.802
24.72
0.781
Finger
42.00
0.983
32.22
0.932
28.56
0.894
4. EXPERIMENTAL RESULTS
Figure 4.System configuration of CUP. DMD, digital micromirror device; CMOS, complementary metal–oxide-semiconductor.
Figure 5.Measuring temporal evolution of a spatially modulated picosecond laser spot. (a) Experimental design. (b)–(d) Reconstructed results by the , AL, and TwIST algorithms, respectively. (e) Measured static image by external CCD. (f)–(h) Extracted images from (b)–(d), respectively, at the time of 14 ps; curves on the right are the integration results of the corresponding images along the horizontal direction.
Here, the static image is achieved by external CCD measurement without encoding operator and shearing operator , as shown in Fig. 5(e). Meanwhile, the intensities of Figs. 5(e)–5(h) are also integrated along the horizontal direction, and the calculated results are given on the right of the relative images. The algorithm can retain very high image fidelity, but the AL and TwIST algorithms cause a certain degree of image distortion. The fundamental reason should be the mismatch of the sparse domain in image reconstruction. More importantly, like the static image, the blocked part in the laser spot (see light blue squares) can be clearly distinguished by the algorithm, where an obvious valley in the intensity curve is observed, but not by either the AL or TwIST algorithm, especially the TwIST algorithm.
Figure 6.Measuring wavefront movement by obliquely illuminating a collimated femtosecond laser pulse on a transverse fan pattern. (a) Experimental design. (b)–(d) Reconstructed results by the , AL, and TwIST algorithms, respectively. (e) Measured static image by external CCD. (f)–(h) Integrated images from (b)–(d), respectively. (i)–(l) Results of Fourier transform from (e)–(h), respectively.
The algorithm is a data-driven method, which can optimize the sparse domain and relevant iteration parameters by learning instead of hand-crafted determination. For CS, the sparse domain is the core part that determines the sparsity and affects mainly the coherence. Thus, the sparse domain almost determines the image reconstruction quality. In general, the learning method can seek better sparse domain and iteration parameters, and therefore the algorithm can get higher image fidelity than conventional AL and TwIST algorithms. Because of learning the sparse domain and iteration parameters, the algorithm has high robustness and allows the encoding operator to be different in training and testing processes, while the pure neural network algorithms cannot, such as deep fully connected networks [58], ReconNet [59], DR2-Net [60], -net [38], and DeepCubeNet [61]. Also, the algorithm embeds a GD algorithm into tensor computation, which involves massive data. In calculation, the GD algorithm does not easily find the appropriate step size, so it needs to perform many iterations, i.e., the convergence speed is low. To decrease the number of iterations, data scientists prefer Newton’s method or a conjugate gradient algorithm by increasing the cost of each iteration [62]. However, some mathematicians seek a better step size in the GD algorithm to decrease the number of iterations by increasing the cost of each iteration, such as the BB method. Here, we utilize the GD algorithm to calculate the large data by a data-driven method based on the learning model, which can find the optimal step size to decrease the number of iterations without increasing the cost of each iteration and make the gradient show better orthogonality. It is noted that the algorithm needs just 15 iterations, while the corresponding traditional algorithm based on the BB method needs more than 100 iterations.
As shown in Figs. 3, 5, and 6, compared to the AL and TwIST algorithms, the algorithm shows great advantages in image reconstruction accuracy, but it also inherits the shortcoming of the data-driven method, i.e., the dependence on a learning dataset. In image reconstruction, these images in the dataset should have some similarities to those in the dynamic scene. An inappropriate training dataset may lead to results worse than those obtained by the AL and TwIST algorithms. In some special dynamic scenes, it may be difficult to find a similar dataset for training. In this case, it is feasible to increase the sampling rate , such as lossless-CUP or multi-encoding CUP. Moreover, it is also a good idea to optimize the codes, which is similar to optimizing the sparse domain, which can reduce coherence. However, the algorithm cannot be adopted directly to optimize the codes, because here the codes are considered as constant. Optimizing the codes demands that the mathematical architecture regard the codes as a variable; thus, the whole architecture needs to be redesigned. In the future, we will strive to seek some new algorithms to simultaneously optimize the codes, sparse domain, and iteration parameters by learning the dataset.
6. CONCLUSION
In summary, we have developed a new algorithm to realize high-fidelity image reconstruction for CUP. In our method, there are four key points: (1) optimizing the sparse domain in multiple transformation; (2) optimizing the relevant calculation parameters in the iteration process; (3) employing the GD algorithm to improve computing efficiency; (4) embedding the U-net architecture to help denoise. Key points (1), (2), and (4) are implemented by the DL method, and improving key point (3) also needs the DL method. However, the whole framework is determined by the AL method, which combines these four key points. Thus, the algorithm not only utilizes the training neural networks, but also has some potential mathematical interpretations. More importantly, these results from theoretical simulations and experimental measurements show that the algorithm is superior to conventional AL and TwIST algorithms in image fidelity and computing efficiency. Additionally, the algorithm is a simple mathematical architecture, so it is easy to extend to other high-dimensional tensor fields. In future studies, we will continue to search for better image reconstruction algorithms for CUP to achieve super-high image fidelity.
[31] J. Zhang, B. Ghanem. ISTA-Net: interpretable optimization-inspired deep network for image compressive sensing. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1828-1837(2018).
[32] J. Ma, X. Liu, Z. Shou, X. Yuan. Deep tensor ADMM-net for snapshot compressive imaging. Proceedings of the IEEE International Conference on Computer Vision, 10223-10232(2019).
[36] L. Wang, C. Sun, Y. Fu, M. H. Kim, H. Huang. Hyperspectral image reconstruction using a deep spatial-spectral prior. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 8032-8041(2019).
[38] X. Miao, X. Yuan, Y. Pu, V. Athitsos. Lambda-net: reconstruct hyperspectral images from a snapshot measurement. IEEE/CVF International Conference on Computer Vision (ICCV), 4058-4068(2019).
[44] M. Raydan. Convergence properties of the Barzilai and Borwein gradient method(1991).
[45] B. Lim, S. Son, H. Kim, S. Nah, K. Mu Lee. Enhanced deep residual networks for single image super-resolution. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 136-144(2017).
[46] L. Yue, X. Miao, P. Wang, B. Zhang, X. Zhen, X. Cao. Attentional alignment networks. 29th British Machine Vision Conference, 1-14(2018).
[47] S. Min, X. Chen, Z. Zha, F. Wu, Y. Zhang. A two-stream mutual attention network for semi-supervised biomedical segmentation with noisy labels. Proceedings of the AAAI Conference on Artificial Intelligence, 4578-4585(2019).
[49] Y. Huang, X. Cao, X. Zhen, J. Han. Attentive temporal pyramid network for dynamic scene classification. Proceedings of the AAAI Conference on Artificial Intelligence, 8497-8504(2019).
[50] D. P. Kingma, J. Ba. Adam: a method for stochastic optimization(2014).
[51] S. H. Chan, R. Khoshabeh, K. B. Gibson, P. E. Gill, T. Q. Nguyen. An augmented Lagrangian method for video restoration. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 941-944(2011).
[55] H. Yu, S. Winkler. Image complexity and spatial information. Fifth International Workshop on Quality of Multimedia Experience (QoMEX), 12-17(2013).
[59] K. Kulkarni, S. Lohit, P. Turaga, R. Kerviche, A. Ashok. ReconNet: non-iterative reconstruction of images from compressively sensed measurements. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 449-458(2016).