
Zhihong Zhang, Kaiming Dong, Jinli Suo, Qionghai Dai, "Deep coded exposure: end-to-end co-optimization of flutter shutter and deblurring processing for general motion blur removal," Photonics Res. 11, 1678 (2023)
- Photonics Research
- Vol. 11, Issue 10, 1678 (2023)
Abstract
1. INTRODUCTION
Due to the limited frame rate of imaging devices and the inevitable instability during capturing, motion blur has become a common problem in daily photography. It not only degrades the photo’s visual quality, but also imposes a great challenge on subsequent high-level vision tasks such as image classification [1], object detection [2], and object tracking [3]. To cope with this problem, various postprocessing deblurring algorithms have been designed by the computer vision (CV) community in the past decades [4–6]. On the other hand, researchers from the computational imaging (CI) field have also proposed many approaches to tackle this problem by jointly considering the imaging and postprocessing processes [7–13]. Coded exposure photography [14] is one of the most representative methods among these approaches, and has received much attention since being proposed [15–20].
A. Coded Exposure Photography
Different from conventional photography keeping the camera’s shutter open throughout the entire exposure elapse, the coded exposure technique flutters the shutter open and closed according to the designed binary sequence in the exposure duration. In this manner, the captured blurry images can better preserve high-frequency details, thus facilitating a subsequent deblurring process [14]. For simplicity, we take one-dimensional (1D) motion as an instance to explain the underlying mathematical principle. It is known that the spatially uniform blur can be formulated as the convolution between the sharp image and the blur kernel, which is determined by the motion trajectory and the exposure pattern (i.e., the flutter shutter). The difference between conventional and coded exposure is demonstrated in Fig. 1.
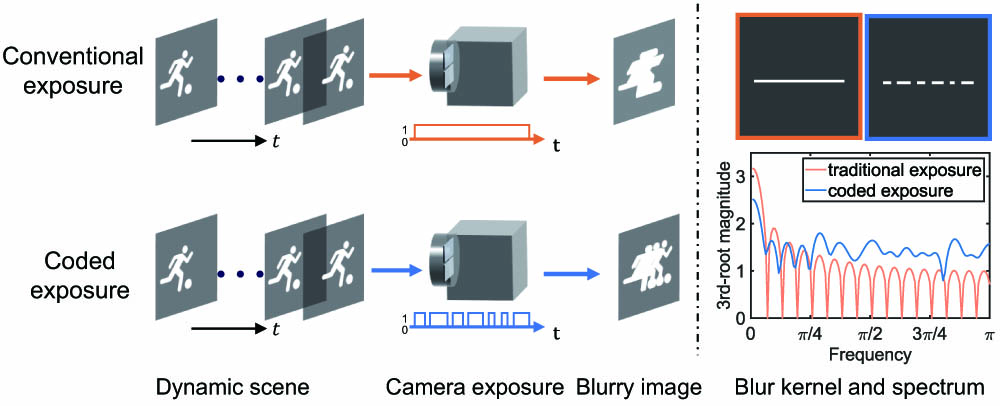
Figure 1.Physical formation of blurring artifacts under conventional and coded exposure settings, and analysis in spatial and frequency domains.
From the spatial perspective, under conventional exposure the resulting blur kernel is a continuous line, and the corresponding blurry image features continuous blurry edges accordingly. By contrast, the blur kernel under coded exposure is an intermittent line and produces edge fringes along the motion trajectories, which is a superimposition of a sequence of sharp snapshots.
Sign up for Photonics Research TOC. Get the latest issue of Photonics Research delivered right to you!Sign up now
From the frequency perspective, the blurring process can be regarded as a frequency sampling or filtering operation since convolution in the spatial domain is equivalent to multiplication in the frequency domain [21]. As can be seen from Fig. 1, the spectrum of the blur kernel resulting from conventional exposure is a band-limited sinc function with periodic zeros and significant attenuation at higher frequencies, so the deblurring is strongly ill-posed. On the contrary, the spectrum of the blur kernel under coded exposure has no zeros and features a relatively flat magnitude across the whole spectrum. Therefore, by controlling the camera shutter with specially designed binary sequences, coded exposure photography can better preserve information of different frequencies and facilitate inverting the blur artifacts to obtain sharp images.
B. Coded Exposure Based Image Deblurring
Based on the fundamental principle of coded exposure deblurring, many works seeking to explore efficient exposure patterns (i.e., the coding sequence) have popped up. In the original paper of coded exposure photography [14], Raskar
Although various criteria for encoding sequence design have been proposed, and corresponding kernel estimation and deblurring algorithms are both improved, there still exist significant drawbacks for existing coded exposure deblurring methods. On the one hand, previous encoding sequence design is mainly based on handcrafted criteria and relies on random searching to find the optimal code. However, handcrafted criteria can hardly make extensive use of the natural image prior, which is important in image restoration. Besides, the random searching strategy is usually inapplicable in long sequence design due to its exponential expanding of search space. On the other hand, most coded exposure deblurring algorithms are still limited to handling uniform (i.e., spatially invariant) blur and rely on tedious pipelines involving foreground segmentation, blur kernel estimation, deblurring, compositing, etc., to finish the deblurring task. These issues greatly limit their applications in motion-blur-free photography.
C. Deep Learning Based Image Deblurring
In recent years, deep learning has been popularized to cope with various CV problems and achieves significant performance promotion compared with conventional algorithms [24]. Benefiting from the powerful representation ability of deep neural networks (DNNs), novel learning-based deblurring methods have been developed and successfully applied to handling the tough spatially varying/nonuniform blur [6]. Besides, these methods also eliminate the preliminary step of blur kernel estimation involved in traditional deblurring algorithms and operate in an efficient end-to-end manner, which is called blind deblurring. Instead of formulating the blurring model as the convolution between a sharp image and the blur kernel, recent learning-based deblurring algorithms directly average consecutive video frames to synthesize the blurry image so as to simulate the more general cases. Nah
Although DNN-based deblurring algorithms have surpassed conventional optimization, which is of inferior performance, tedious pipelines, and significant limitations in practical applications, they have also encountered bottlenecks. On the one hand, the high frequencies lost in the blurry images or the intrinsic ill-posedness of the deblurring problem determine the performance upper-bound of learning-based algorithms. Even though some generative networks such as the variational autoencoder (VAE) [31] and generative adversarial networks (GANs) [32] could produce plausible results by imposing strong priors of nature scenes, they cannot reconstruct perfect results in image restoration problems. On the other hand, after years of progress in network design and hyper-parameter fine-tuning, the performance advances of deblurring neural networks have slowed down, but the practical applicability is still largely limited, especially in scenarios with complex motion or realistic noise. Fortunately, recent advances in high-level CV tasks such as semantic information retrieval have demonstrated that combining both CI and CV [33–35] to draw on each other’s strengths can gain an overall performance promotion. Inspired by this new trend, we revisit coded exposure deblurring and combine it with recent advances in deep learning to unlock insights to boost the deblurring performance and broaden its applicability.
D. Contributions of this Paper
Here we propose a novel single-image motion deblurring framework incorporating a coded exposure based imager and a learning-based deblurring network jointly. We co-optimize the imager’s exposure pattern and the parameters of the deblurring network to achieve an optimal overall performance while avoiding the high-complexity exhaustive search of the encoding sequence and complex preprocessing steps. Besides, with the aid of deep learning’s powerful representation ability, we loosen the strict assumptions of previous coded exposure based deblurring methods and can handle general motion blur blindly. To the best of our knowledge, this is the first work applying coded exposure photography in learning-based end-to-end blind nonuniform deblurring.
The contributions of this work can be summarized as follows.
2. ENCODER–DECODER CO-OPTIMIZATION FRAMEWORK
The overall flowchart of the proposed coded exposure blur encoding and learning-based deblurring co-optimization framework is demonstrated in Fig. 2. In the training stage, we model the physical imaging process as an optical blur encoder in accordance with the fundamental principle of coded exposure photography. Then, a CNN-based blur decoder is employed to estimate the latent sharp image from its coded blurry counterpart generated from the optical blur encoder. It is worth noting that both the optical blur encoder and the CNN-based blur decoder are optimized jointly during the training period. In this manner, the encoding sequence of the coded exposure and the parameters of the deblurring CNN will be updated simultaneously, allowing us to find a solution superior to the separate optimization. In the inference phase, the optical blur encoder is replaced with the real acquisition process, and the optimized encoding sequence is loaded to a camera as the shutter trigger signal accordingly. The trained CNN model will also be saved to perform the deblurring task for the real-captured coded blurry images.
![]()
Figure 2.Overall flowchart of the proposed framework. The coded exposure imaging system and the learning-based deblurring algorithm are respectively modeled with an optical blur encoder and a computational blur decoder, and together form an end-to-end differentiable forward model. In the training stage, the parameters of the whole model are optimized together through gradient descent until convergence. In the inference stage, the learned encoding sequence will be loaded to the controller of the camera shutter (or its equivalent), and the computational blur decoder will be employed to deblur the captured coded blurry images.
In the following subsections, we will give a detailed description about the design and implementation of each module in the framework.
A. Learnable Optical Blur Encoder
To describe general nonuniform blurry images efficiently, we discard the convolution-based blur simulation method widely used in previous works. Instead, recalling that the digital camera records a blurry image by continuously accumulating light signals from a dynamic scene on the sensor during the exposure period, we thus regard the blurry snapshot as a summation of sharp images describing the scene in a continuous sequence of sufficiently short time slots. When taking the coded exposure into consideration, some of the exposure segments corresponding to the “close-shutter” state will be blocked out during the sensor integration. Therefore, the exposure encoding sequence actually serves as binary weights for these sharp images during the integration. Denoting the exposure duration as
The selection of the encoding sequence is intrinsically a binary optimization problem, which is difficult for both conventional optimization and deep learning. Fortunately, there are mature solutions in deep learning to enable back-propagation training of binary parameters, and we employ a widely used technique called “straight-through-estimator” (STE) [36,37] in our work. Specifically, in the optical blur encoder, instead of directly defining a binary encoding sequence, we employ the reparameterization trick [31] by introducing a learnable parameter vector
B. Learning-Based Blur Decoder
With the flourishing development of deep learning, a number of deep deblurring neural networks have been proposed and achieved superior performance to traditional optimization-based methods [5,6]. In the proposed co-optimization deblurring framework, we employ a SOTA deblurring CNN called DeepRFT [29] to estimate the latent sharp image from its coded blurry counterpart. As an end-to-end blind deblurring method, DeepRFT eliminates the tedious blur kernel estimation and pre-/post-processing steps required in conventional coded exposure deblurring methods.
The basic architecture of DeepRFT is shown in Fig. 3. It employs an MIMO-UNet [28] empowered by several specially designed feature extraction and fusion modules. Like many other deblurring networks, DeepRFT adopts the multi-scale strategy to facilitate deblurring by aggregating information from various spatial scales. Specifically, it first down-samples the blurry images to generate another two blurry images that are half and a quarter of the original spatial resolution, respectively. Then these three blurry images are sequentially input to the network and deblurred at different stages. Accordingly, multi-scale losses are employed during training to measure the distance between the outputs of different spatial scales and their respective ground truth. DeepRFT further replaces the vanilla convolution layer with the depth-wise over-parameterized convolutional layer (DO-Conv) [38] to achieve additional performance gains. DO-Conv is realized by enhancing the conventional convolution layer with an additional depth-wise convolution that convolves each input channel with a different two-dimensional (2D) convolution kernel, and has demonstrated superior performance in many vision tasks. The uppermost contribution of DeepRFT lies in proposing a novel Res-FFT-Conv Block, which augments the canonical ResBlock [39] with an extra frequency-domain convolution branch. The branch is implemented with 2D fast Fourier transformation (FFT), and helps to provide supplementary information from the frequency domain. In brief, the designed Res-FFT-Conv Block can effectively model the frequency discrepancies between the blurry and sharp image pairs, and can also capture both the long-term and short-term interactions to facilitate the deblurring process.
![]()
Figure 3.Architecture of the deblurring neural network DeepRFT [29] in the proposed framework.
It is worth noting that although we choose DeepRFT as the coded blur decoder in the current implementation of the proposed framework thanks to its superior performance and low computation complexity, it can be flexibly switched to other learning-based deblurring networks to keep up with the latest advances in the CV deblurring field.
C. Loss Function
The loss function for model training consists of the following three terms.
Multi-scale Charbonnier loss [27] penalizes the deviation of the estimated sharp image from its ground-truth version at different spatial scales:
Multi-scale edge loss is defined as [27]
Multi-scale frequency reconstruction loss [28] is also introduced to guide the prediction towards the latent sharp image but defined in the Fourier domain
The final loss function is defined as a weighted summation
D. Prototype Building
Coded exposure imaging requires the camera to flutter its shutter according to the designed binary encoding sequence during the exposure period. Although not commonly used on commercial cameras, this feature can be implemented with photoelectric devices. One can either introduce an extra external shutter synchronized by a micro-controller [14] or directly employ the cameras supporting IEEE DCAM Trigger Mode 5 [15,19,22] to customize the exposure sequence. For simplicity and high compatibility with most commercial cameras, we adopt the external shutter scheme to validate the proposed approach.
The prototype of our coded exposure imaging system is shown in Fig. 4. Apart from the conventional RGB camera (JAI GO-5000C-USB), it also consists of a liquid crystal optical shutter (Thorlabs LCC1620), a camera lens (KOWA, 12.5 mm/F1.4), and a micro-controller (Arduino Nano). The liquid crystal optical shutter is composed of a liquid crystal cell sandwiched between a pair of orthogonal polarizers. It has an average transmittance above 60% in the open state over the visible-light wavelength range and a contrast ratio (defined as the ratio of the transmittance in the open state to the transmittance in the close state) exceeding 8000:1. During acquisition, the micro-controller produces optimized binary voltage signals to control the shutter’s open/close state by changing the liquid crystal’s molecule orientation. Meanwhile, the micro-controller also functions to synchronize the camera with the shutter.
![]()
Figure 4.Prototype system for coded exposure photography. It employs a liquid crystal element to serve as an external shutter for exposure encoding.
3. EXPERIMENTS
A. Implementation Details
In the following experiments, we employ the widely used high-frame-rate video dataset GoPro [25] to simulate coded blurry snapshots, train our network, and evaluate the proposed framework’s performance. GoPro dataset is acquired using a GOPRO4 Hero Black camera at 240 frames per second (FPS). It contains approximately 35,000 sharp images in total, about two thirds of which are used for training and the rest for testing. Unless otherwise stated, the length of the exposure encoding sequence is set to 32 in the experiments; i.e., 32 sharp images from the dataset would be weighted by the binary encoding sequence and then collapsed to a single coded blurry image by the optical blur encoder. Besides, we also normalize the coded blurry images to [0,1] and add Gaussian noise with a standard deviation ranging from 0 to 0.02 to mimic the physical imaging process.
We implement the framework with PyTorch [40] and conduct the experiments on a workstation equipped with an AMD Ryzen Threadripper 3970X CPU and an NVIDIA GeForce RTX 3090 GPU. In the training phase, we adopt the Adam optimizer [41] to update the parameters and initialize the learning rate to
It is worth noting that the STE technique might introduce instability during training, and thus we employ a multi-step training strategy to mitigate this issue. Specifically, the learning-based blur decoder (DeepRFT) is first pretrained for 150 epochs with the parameters of the optical blur encoder fixed, and then the whole framework is trained for another 450 epochs until converged.
B. Performance Evaluation and Analysis
To quantitatively evaluate the performance of the proposed co-optimization framework, we first compare them with the conventional noncoded deblurring method and SOTA coded exposure deblurring methods [14,15,23,44]. As mentioned above, most existing approaches focus on the design of exposure encoding sequences while employing traditional optimization-based deblurring algorithms and assuming uniform blur kernels. However, in this work, we aim for the more general blind and nonuniform deblurring problem. Therefore, for a fair comparison, we only change the encoding sequence in the optical encoder according to the competing methods, and adopt the same deblurring network architecture in the blur decoder to conduct blind nonuniform deblurring. Besides, for different encoding sequences, the deblurring network is separately trained from scratch on the same dataset.
The performance of different exposure codes is compared in terms of the peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) on the GoPro dataset. The results are listed in Table 1, arranged by the time being proposed. Two deblurring experiments conducted on a spatially invariant blurry image (the “cars”) and a spatially varying blurry image (the “flowers”) are shown in Fig. 5 for visual comparison as well. It can be observed that the proposed co-optimization deblurring framework demonstrates a significant improvement over all competing methods, and its PSNR and SSIM gains compared with the second-best competitor by Cui
Deblurring Performance with Different Encoding Sequences
| Methods | Noncoded | Raskar | Agrawal and Xu [ | Jeon | Cui | |
|---|---|---|---|---|---|---|
| Sequence (Hex) | FFFFFFFF | F1CD448D | 7FFC2747 | 16A3809B | 8076A061 | |
| PSNR (dB)/SSIM | 24.56/0.7695 | 24.37/0.7638 | 24.60/0.7695 | 25.47/0.8035 | 26.66/0.8289 |
The encoding sequences are written in hexadecimal for simplicity.
![]()
Figure 5.Synthesized blurry images under different exposure encoding settings and corresponding deblurring results. (Please zoom in for a better view.)
From Table 1, we can also observe that nearly all of the coded exposure deblurring methods achieve superior performance to the noncoded deblurring method, and their performance features a monotone increasing tendency, which validates the higher effectiveness of novel encoding sequence design criteria than the elder ones. Note that, different from other coded exposure deblurring methods, Raskar
![]()
Figure 6.Frequency spectra of different encoding sequences.
Next, we conduct another ablation experiment to study the influence of the sequence length on our deblurring performance. Learnable encoding sequences of 8, 16, 32, and 64 bits are tested in this experiment. Different from the previous evaluations, we use 64 consecutive sharp frames from the GoPro dataset to serve as the blur encoder’s original input. Note that we keep the number of input frames constant throughout the experiment to simulate different coded blurry images taken under the same exposure time. To match the length of the encoding sequences with the number of input frames, we upsample the 8-bit, 16-bit, and 32-bit encoding sequences to 64-bit beforehand.
We report our experimental results in Fig. 7, from which one can observe that the deblurring performance of our framework increases monotonically with the increase of the sequence length. In other words, for a specific exposure time, a longer encoding sequence will result in better deblurring performance. From the imaging perspective, given a certain duration of the total exposure, a longer encoding sequence corresponds to a shorter exposure elapse for each bit of the sequence, and the corresponding images will be sharper accordingly. From the optimization perspective, having more bits in the encoding sequences will result in a larger searching space, which facilitates finding a better solution. It is worth noting that, in practice, there are still some limitations in increasing the length of encoding sequences. On the one hand, in network training, a longer encoding sequence means more sharp frames are required to synthesize a coded blurry image. The huge data will impose much pressure on the memory consumption, making it the bottleneck for efficient training. On the other hand, in hardware implementation, the length of the encoding sequence in a single exposure will be restrained by the refresh rate of the external programmable shutter.
![]()
Figure 7.Influence of the encoding sequence’s length on the deblurring performance of the proposed framework.
C. Qualitative Demonstration on Real Data
In order to validate the effectiveness of the proposed framework in real scenarios, we also use the built prototype system to capture encoded blurry snapshots of highly dynamic scenes and reconstruct their sharp versions computationally. In the experiment, we build an exemplar scene that contains a horizontally moving car and a swinging flower to generate spatially varying 1D and 2D motion blurs. The system is placed approximately 50 cm in front of the scene. During acquisition, the exposure time of the camera is set to 0.8 s, and thus each bit in the 32-bit encoding sequences corresponds to 25 ms. The captured blurry images are transferred from the sensor to the workstation through a universal serial bus (USB). Afterward, these images are deblurred with the corresponding pretrained deblurring models. Averagely, it takes about 0.52 s to handle one blurry image of
Figure 8 shows the captured blurry images and corresponding deblurring results of our approach and other existing coded exposure photography methods. One can observe that the recovered sharp image of our co-optimization deblurring framework features sharper structures and clear background across different regions. By contrast, the noncoded deblurring method and existing coded deblurring methods suffer from more artifacts and lower definition.
![]()
Figure 8.Real-captured blurry images under exposure with different encoding sequences and corresponding deblurring results. (Please zoom in for a better view.)
4. CONCLUSION AND DISCUSSION
In summary, we revisit the coded exposure technique and propose a novel co-optimization deblurring framework for simultaneous exposure pattern design and blind nonuniform image deblurring. To the best of our knowledge, this is the first work investigating the application of coded exposure photography in learning-based end-to-end blind nonuniform deblurring. By integrally modeling the whole process of blurry image formation and sharp image estimation in a differentiable manner, the proposed framework empowered by deep learning achieves superior performance to the separate optimization. Besides, compared with the previous exposure designs based on hand-crafted criteria and random searching, the proposed framework takes natural image prior into consideration via data-driven network training and solves the nondifferentiable issue in binary sequence optimization. Both the simulation experiments on standard datasets and the real-data experiments on our prototype have validated the effectiveness of the proposed approach.
Note that the objective of this work is to design a general deblurring framework combining CI and CV to bridge the gap between the coded exposure technique and recent advances in learning-based deblurring algorithms, rather than developing a specific SOTA network architecture for the image deblurring task. Therefore, the framework can flexibly incorporate other learning-based deblurring networks to keep up with the latest advances in the CV deblurring field. Besides, recent development in novel binary neural networks could also provide possible variants for our network. We leave the extensions to future investigations.
In the future, this work can be further extended in the following two directions. From the algorithm perspective, the network architectures of the binary-modulation blur encoder and the coded blur decoder in the proposed framework could be investigated and improved to achieve higher deblurring quality and faster inference speed. From the application perspective, apart from the coded motion blur, other types of blur resulting from out-of-focus or lens aberration could also be involved in designing a more comprehensive blur encoder, making it possible for the framework to cope with more complex blur artifacts in an end-to-end manner. Furthermore, a more realistic noise model could also be employed in training data simulation to raise the deblurring network’s robustness in low-light conditions.
References
[2] S. Zheng, Y. Wu, S. Jiang, C. Lu, G. Gupta. Deblur-YOLO: real-time object detection with efficient blind motion deblurring. International Joint Conference on Neural Networks (IJCNN), 1-8(2021).
[4] R. Wang, D. Tao. Recent progress in image deblurring. arXiv(2014).
[9] S. McCloskey. Temporally coded flash illumination for motion deblurring. International Conference on Computer Vision (ICCV), 683-690(2011).
[13] C. M. Nguyen, J. N. P. Martel, G. Wetzstein. Learning spatially varying pixel exposures for motion deblurring. IEEE International Conference on Computational Photography (ICCP), 1-11(2022).
[15] A. Agrawal, Yi Xu. Coded exposure deblurring: optimized codes for PSF estimation and invertibility. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2066-2073(2009).
[16] A. Agrawal, R. Raskar. Optimal single image capture for motion deblurring. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2560-2567(2009).
[17] S. McCloskey. Velocity-dependent shutter sequences for motion deblurring. Computer Vision–ECCV, 309-322(2010).
[18] S. Harshavardhan, S. Gupta, K. S. Venkatesh. Flutter shutter based motion deblurring in complex scenes. Annual IEEE India Conference (INDICON), 1-6(2013).
[19] H.-G. Jeon, J.-Y. Lee, Y. Han, S. J. Kim, I. S. Kweon. Complementary sets of shutter sequences for motion deblurring. IEEE International Conference on Computer Vision (ICCV), 3541-3549(2015).
[21] R. Gonzalez, R. Woods. Digital Image Processing(2017).
[25] S. Nah, T. H. Kim, K. M. Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 257-265(2017).
[26] X. Tao, H. Gao, X. Shen, J. Wang, J. Jia. Scale-recurrent network for deep image deblurring. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 8174-8182(2018).
[27] S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, L. Shao. Multi-stage progressive image restoration. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 14816-14826(2021).
[28] S.-J. Cho, S.-W. Ji, J.-P. Hong, S.-W. Jung, S.-J. Ko. Rethinking coarse-to-fine approach in single image deblurring. IEEE/CVF International Conference on Computer Vision (ICCV), 4621-4630(2021).
[30] K. Kim, S. Lee, S. Cho. MSSNet: multi-scale-stage network for single image deblurring. Computer Vision–ECCV, 13802, 524-539(2023).
[31] D. P. Kingma, M. Welling. Auto-encoding variational bayes. arXiv(2022).
[36] M. Courbariaux, Y. Bengio, J.-P. David. BinaryConnect: training deep neural networks with binary weights during propagations. Advances in Neural Information Processing Systems (NeurIPS), 28(2015).
[37] I. Hubara, M. Courbariaux, D. Soudry, R. El-Yaniv, Y. Bengio. Binarized neural networks. Advances in Neural Information Processing Systems (NeurIPS), 29(2016).
[39] K. He, X. Zhang, S. Ren, J. Sun. Deep residual learning for image recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778(2016).
[40] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala. PyTorch: an imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems (NeurIPS), 8024-8035(2019).
[41] D. P. Kingma, J. Ba. Adam: a method for stochastic optimization. arXiv(2017).
[42] I. Loshchilov, F. Hutter. SGDR: stochastic gradient descent with warm restarts. 5th International Conference on Learning Representations (ICLR)(2017).
[43] X. Chu, L. Chen, C. Chen, X. Lu. Improving image restoration by revisiting global information aggregation. Computer Vision–ECCV, 53-71(2022).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20