
Xuyu Zhang, Shengfu Cheng, Jingjing Gao, Yu Gan, Chunyuan Song, Dawei Zhang, Songlin Zhuang, Shensheng Han, Puxiang Lai, Honglin Liu, "Physical origin and boundary of scalable imaging through scattering media: a deep learning-based exploration," Photonics Res. 11, 1038 (2023)
- Photonics Research
- Vol. 11, Issue 6, 1038 (2023)
Abstract
1. INTRODUCTION
Light scattering within and through complex media poses great challenges for many hotspot applications, including deep tissue imaging, antiscattered data transmission, etc. [1–3]. For example, biological tissues are usually optically turbid, which causes light to diffuse rapidly and prevents high-resolution focusing inside deep tissue. To ensure the imaging resolution, most optical microscopes [4–6] select ballistic photons for imaging with an imaging depth limited within an optical diffusion limit () [7]. Strong optical scattering also prevents explicit data communication through complex media where the input light is scrambled into a seeming random speckle pattern. Luckily, the process is still deterministic, which allows for the recovery of objects hidden behind scattering media.
Various methods for imaging through scattering media have been developed over the past two decades, such as object reconstruction via the transmission matrix (TM) [8,9], speckle correlation imaging [10–12], and single-pixel imaging [13,14]. These methods can retrieve the object information noninvasively, yet encounter limitations either in field of view (FOV) or reconstruction speed. Especially, they are all sensitive to the TM of scattering medium and any change may lead to model errors. Recently, deep learning (DL) approaches have been introduced to invert scattering [15,16] and reconstruct an object through complex media [17–21], showing superior recovery quality and extended FOV than the range of optical memory effect [22]. Initially, the DL-related studies are only applicable to a specific diffuser and cannot adapt to varying scattering conditions. Later, efforts have been taken in overcoming the speckle decorrelation and achieving highly scalable imaging through scattering media [23–26], through optimizing the network model or training strategy. Those include adopting a “one-to-all” training strategy to enable a network learning the statistical information of multiple diffusers [23], integrating the prior knowledge of speckle correlation theory for physics-informed learning [25], or proposing a dynamic synthesis network (DSN) with robust 3D descattering ability [26], etc. However, the origin of such model generalization is unclear, and it sees limitations for thick scattering media or dynamic scattering conditions. Currently, there is a lack of research from the perspective of physics to reveal the origin and boundary of the scalability of a DL model, which is important in applying DL to scalable imaging through scattering media with high confidence.
In this paper, we investigate how the scattering property of a medium can influence the adaptivity of a reconstruction model. Specifically, we find the amount of (quasi-)ballistic photons in the output light field, which directly reflects the medium’s scattering property, is closely related to the general applicability of the model. Our findings are verified by both experimental and simulated results. In experiment, utilizing a homemade diffuser of relatively weak scattering, much improved adaptivity of a reconstruction network is obtained when trained with data sampled from different regions of the diffuser. To separately study the influences of model training strategy and the scattering property of a diffuser, simulations are performed in which different weights of ballistic component are tested thanks to the adjustable phase distribution of a simulated diffuser. It is revealed that the ballistic light plays a key role in the applicability of a model to unseen diffuser (region): it is lost when there is no ballistic component whatever training strategy is used; it is enhanced proportionally with increasingly larger weight of ballistic light even if the network only saw one specific diffuser (region) before. The physical origin and boundary for the general applicability of a DL model are further clarified. In addition, our mechanism findings provide guidance for enhancing the generalization performance of DL to scalable descattered imaging.
Sign up for Photonics Research TOC. Get the latest issue of Photonics Research delivered right to you!Sign up now
2. METHODS
A. Experimental Implementation
The experimental setup is illustrated in Fig. 1. A beam from a 532 nm solid-state laser (MGL-III-532–200 mW, Changchun New Industries Optoelectronics Tech.) is first expanded before being collimated onto a digital micromirror device (DMD, V-7001 VIS, ViALUX). The modulated light then illuminates a homemade 220 grit ground glass diffuser. An iris with a diameter of 5 mm is placed right after the diffuser, which creates a tunable window to control the region of imaging through the diffuser. The transmitted light travels a distance before being collected by an on-axis digital camera (DCU224M, Thorlabs). The distances from the beam expander to the DMD, from the DMD to the diffuser, and from the diffuser to the camera are , , and , respectively.
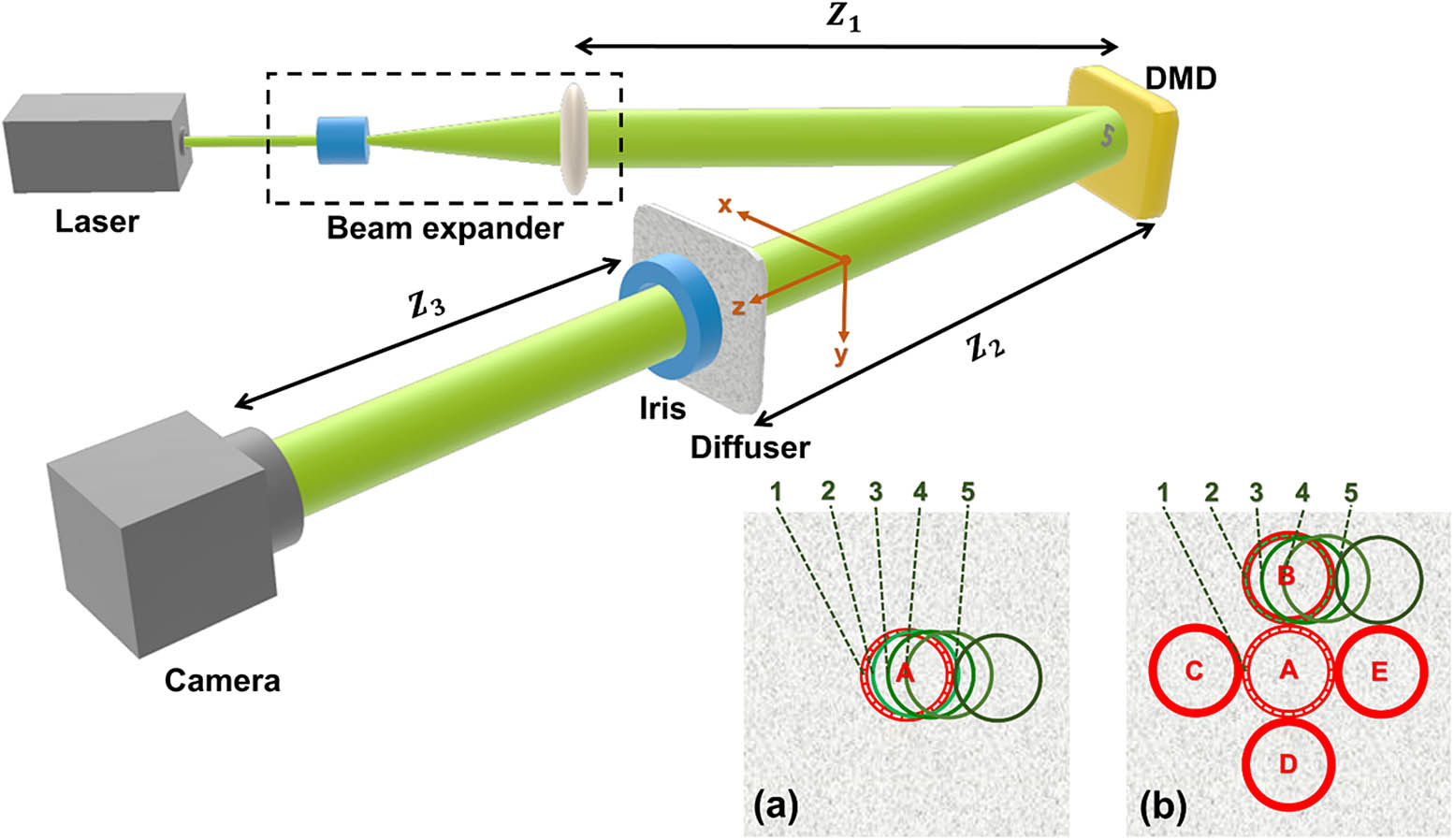
Figure 1.Schematic of the experimental setup of imaging through a diffuser with the coordinate system labeled. The insets (a) and (b) show the settings of imaging regions to acquire the training and test data in Tests I and II, respectively. In Test I, the training data were obtained from region
According to the Van Cittert–Zernike theorem [27], the spatial coherence length (SCL) in our diffraction imaging system, is described by , where is the optical wavelength and is the aperture size of the iris. SCL approximates the average size of speckle on the camera plane, which was about two to three times of the pitch of the camera pixel. To accelerate data processing, the central area of the originally acquired speckle pattern was cropped into and then down sampled into a array. To quantify the isoplanatic range, i.e., the average grain size of the diffuser, a point source generated by binning pixels on the DMD was used to illuminate the diffuser. The diffuser was shifted horizontally with the speckle patterns recorded at each displacement () accordingly. The cross-correlation coefficient (CCC) between the speckle pattern recorded at each position and the one at the origin (i.e., ) was calculated. The full width at half maximum (FWHM) of the fitted CCC curve was used to characterize the isoplanatic range, which reflects the spatially variant scattering property of the imaging system. The speckle pattern recorded with a displacement of diffuser larger than the isoplanatic range is regarded as unrelated to the one recorded at the origin.
In our experiment, handwritten digits from the Modified National Institute of Standards and Technology (MNIST) dataset [28] were used as the objects displayed on the DMD. A U-Net model [29] was used for object reconstruction from speckle data. Two tests were performed to validate the effect of adapting a one-to-all network training strategy [23]. The imaging regions for the acquisition of the training and test data in Tests I and II are indicated in the insets Figs. 1(a) and 1(b), respectively. In Test I, 20,000 pairs of training data were acquired only at region . Data from five different regions were used for the network test in which region 1 overlapped with region and regions 2–5 were 10, 40, 100, and 5000 μm, respectively, away from region 1 along the axis. In Test II, 20,000 pairs of data acquired from regions with 4000 pairs at each were used for network training. To test the network, five different sampling regions were also used with region 1 overlapping with region , region 2 overlapping with region , and regions 3–5 being 40, 100, and 5000 μm, respectively, away from region 2. For both Tests I and II, two groups of untrained MNIST digit images (each has 100 images) were selected with their corresponding speckle patterns for the network test.
B. Simulations
1. Diffuser Model
A random phase plate was used to model the diffuser according to the theory of light scattering from rough surfaces in which a Gaussian height distributed surface with a Gaussian autocorrelation function is assumed [30]. The original simulated phase mask has an array of with a pitch size of 5 μm, whereas only a segment of the array was selected as the effective zone each time. The key parameters of the simulated phase mask include the SCL and the standard deviation of height. To model a 220 grit diffuser, the typical values for the two above parameters were 36 μm and 1.6 μm, respectively.
In simulation, the weight of ballistic light () in the transmitted light field was calculated based on the spectrum of the simulated phase mask. Using a coefficient to control the phase distribution range of the mask, the ratios of ballistic and scattered light components were controllable. Specifically, we first calculate the power of the ballistic light, which will correspond to the center zero-frequency spectrum (). However, there are also a few zero-frequency components of the scattered light, which are estimated by calculating the average of the adjacent power spectra around the center spectrum (). The accurate power of the ballistic light () is obtained by subtracting from , and is calculated as the ratio of to the total power (),
The capability of controlling the weight of the ballistic component of an output light field provides much convenience in allowing us to study the ballistic contribution to the adaptivity of a reconstruction model.
2. Output Light Field
The light field detected behind a scattering medium can be regarded as a weighted superposition of the ballistic and scattered light after free-space diffraction propagation,
Here, is the input light field, represents the TM of the medium, is the diffraction operator, and , are the weighting coefficients of ballistic and scattered light fields, respectively. The intensity pattern captured on the imaging plane is as follows:
3. Simulation Settings
For a reconstruction model, it would be easy to extract object information purely from the ballistic component, and such an ability is also scalable to medium perturbation or generalizes to other unknown diffuser. However, with a totally diffused output light field, it would be hard for a model to be scalable if trained with data from a specific diffuser (region). The reason is the model can only learn the specific statistical information of diffuser, which is not generalizable. Therefore, it is natural to hypothesize that the portion of ballistic light in the output field impacts the model scalability. Thanks to the tunable ratio of ballistic component in simulation, we studied its influence on the model adaptivity separately with two tests conducted.
Simulation I. Under the condition of no ballistic component (), two comparative tests similar to the experimental settings were involved. For Test I, the U-Net was trained with 20,000 input–output pairs captured at one diffuser region only and tested on the data obtained from regions 1–9, which were horizontally away from the training region by 0, 10, 35, 40, 100, 1000, 2500, 3500, and 5000 μm. For Test II, data from five regions [also as indicated in Fig. 1(b)] with 4000 pairs at each were used for network training. Again, the trained model was tested on the data acquired from regions 1–9.
Simulation II. Although only allowed to see one diffuser region, the model was trained under varying weights of ballistic light (). For each case, 20,000 data from 1 region were collected to train the U-Net. Additionally, data from six regions (with horizontal shifts of 0, 10, 35, 40, 100, and 5000 μm, respectively) were used for a network test.
For both experiment and simulation, we used the Python programming language and Keras/TensorFlow 2.0 framework for the construction of a U-Net model, which was running on the environment of GPU (NVIDIA RTX 3060 laptop edition). The size of speckle data was . The total number of training epochs was 50, and the learning rate at the beginning was set as . After five epochs, if the loss value did not decrease, the learning rate would be adjusted to one-tenth of the previous one until the learning rate was reduced to . When the loss value did not decrease after 10 epochs, the training would be terminated. The averaged training duration of each epoch was 130 s.
3. RESULTS
A. Experiment Results
Figure 2 presents the results in experimental Tests I and II. A seemly high visual similarity due to a lack of speckle details is found for the testing speckle patterns in Fig. 2(a). This could be attributed to the fact that the speckles were almost not amplified before being captured in our diffraction imaging system. However, the structural similarity index measure between the testing speckle patterns resulting from different categories of MNIST digits is calculated to be less than 0.05, showing a very low level of correlation. For Test I [Fig. 2(a)], the qualitative reconstruction results for those sampled from regions 1–5 are gradually deteriorating. Region 1 has the best quality as it coincides with the training region, which also shows the success of the U-Net in extracting information about unseen objects. The reconstruction quality sees a decline at region 2 but is still acceptable, whereas, getting much poorer at regions 3 and 4, which are only partially “seen” by the network during training. At region 5, the recovered image can no longer be recognized as the network never sees that region before. By contrast, much improved generalization ability to different regions is found for the U-Net in Test II when adopting a one-to-all training strategy. Objects can be perfectly reconstructed at regions 1 and 2, and can still be visually recognized throughout regions 3–5 without much difference in reconstruction quality among them. Note region 5 has no overlapping with the training regions , which means the network can generalize to the unknown region. The quantitative metrics of Pearson correlation coefficient (PCC) are plotted in Fig. 2(b) with those of Test I declining more rapidly than those of Test II. Especially, the average PCC for Test I drops below 0.3 when at , whereas, Test II sees a relatively stable level of PCC at around 0.6 when the test region shifts horizontally by 40–5000 μm.
![]()
Figure 2.Experimental results. (a) Image reconstruction through a homemade diffuser in Tests I and II. (b) Curves of the averaged PCC with error bar for 10 reconstructed images at each of the test regions 1–5. Note a nonuniform abscissa is adopted to better reflect the whole trend, given the nonuniform distributed displacements. (c) The CCC curve measured in experiment with a FWHM of
The above comparisons validate that the generalization capability of a reconstruction network can be considerably improved when trained with multisource data [18]. Figure 2(c) gives the fitted CCC curve of the output light field, whose FWHM is used to denote the isoplanatic range, measured to be . This is consistent with the fast decay of PCC at around 40 μm displacement in Fig. 2(b). The fact that the CCC plateaus around 0.4 suggests there is still an important portion of ballistic light. It looks like that, such as in the presence of ballistic light, the adaptivity of reconstruction model can be enhanced using the one-to-all strategy. However, how ballistic component can contribute to the model adaptivity is still unclear. Therefore, we resort to simulated studies.
B. Simulation Results
In Simulation I, we controlled such that the ballistic light through diffuser was depleted with only scattered light. The phase mask for modeling a diffuser with strong scattering is shown in Fig. 3(a). The characterized CCC curve of the simulated diffuser in Fig. 3(b) reveals an isoplanatic range of . Besides that, a base level of CCC at around 0 confirms the absence of ballistic light in the simulated output field. For both Tests I and II of Simulation I, image reconstruction results from only the odd test regions are presented in Fig. 3(c), whereas all the reconstruction metrics are given in Fig. 3(d). We can see the objects can be well restored at regions 1 and 2 and recognizable at region 3 () although at a decaying quality. Interestingly, in both Tests I and II, the network seems not to reconstruct the objects from region 4 and above, once the displacement is beyond the isoplanatic range. This is confirmed by the high consistence of the PCC curves between the simulated Tests I and II and the experimental Test I within 0.1 mm displacement as shown in the enlarged subplot of Fig. 3(d). This suggests that under the condition of no ballistic component, a reconstruction model hardly generalizes to an unknown diffuser (region) even if adopting a one-to-all training strategy in Test II.
![]()
Figure 3.Results of Simulation I where no ballistic light is involved. (a) The phase map of the simulated diffuser in which the color bar denotes the range of phase value in radian. (b) The characterized CCC curve of the simulated diffuser, which has an FWHM of
Given the above results, we hypothesize the scalability of network observed in experimental Test II is preconditioned with ballistic light component. The scattering component can provide specific statistical information of a diffuser (region), i.e., a decryption key, but is unable to be used solely for training an adaptive network even from multiple sources. The immunity of the ballistic component to the change of scattering condition (e.g., the shift of diffuser region) may play an indispensable role in the model adaptivity.
To confirm the hypothesis, Simulation II was further performed to investigate the influence of ballistic light on the adaptivity of a model when trained with single-source data. The range of phase distribution of the simulated diffuser was adjusted to control , respectively, as seen in Fig. 4(a). The image reconstruction results at different test regions (denoted by ) for each case of are summarized in Figs. 4(b) and 4(c). Qualitatively, it can be observed from Fig. 4(b) that the generalization capability of network to displacements is enhanced with increasing weight of ballistic light (). Such a trend is more straightforward from the PCC curves shown in Fig. 4(c) where one corresponding to a larger is generally at a higher level among all the test regions.
![]()
Figure 4.Results of Simulation II that involves different weights of ballistic light (
At , the average PCCs for different are almost the same, although a slight bias for the case of is observed. The reason may be that the information extraction efficiency of a network from speckle patterns is slightly higher than from diffraction patterns directly as more high-frequency components of an object could be encoded by the former due to the larger scattering angles. Regarding the performance of network generalization at the existence of scattering component (i.e., ), which originates from a specific encryption key, the poorer recovery at a test region is mainly due to the mismatch between the encryption and the decryption keys. We show that such mismatch can be mitigated by increasing weight of ballistic light. According to the CCC curves under different [Fig. 4(d)], the isoplanatic range of the output field grows proportionally with increasing ballistic light. In the extreme case of , the output field is solely the diffracted object [Fig. 4(b) VI] as no scattering is induced by the “flat” diffuser [Fig. 4(a) VI]. Consequently, data from different regions all show the same diffraction characteristic, which means among the output field and the trained network can generalize to unknown diffuser regions freely. Through the above simulation tests, the roles of scattered and ballistic light on the model generalization are clarified. In particular, the latter contributes to the spatial coherence of output field to impact the network scalability.
Our findings provide practicable guidance in enhancing a DL model for scalable imaging through scattering media. In our experiment, a simple way for increasing the weight of ballistic light is to increase the distance since the scattered photons of relatively large divergence angle can be partially filtered out during free-space propagation. This is verified by the experimental results shown in Fig. 5 where both the base level and the FWHM of the CCC curve are improved [Fig. 5(a)], meaning stronger spatial coherence in the output field with larger . Consequently, the performance of network in the generalization Tests I and II is also improved with an increase in [Fig. 5(b)].
![]()
Figure 5.Improved model generalization by increasing distance
4. DISCUSSIONS AND CONCLUSION
Although there have been many DL studies aiming at improving the model generalization for descattered imaging, the origin and boundary of such model scalability from the perspective of physics were still unclear. In this paper, through both experimental and simulated tests, we found the ballistic component was closely related to the model adaptivity. Furthermore, the different mechanisms of scattered and ballistic light for a reconstruction model were revealed. The scattering component was encrypted by a diffuser (region) from which a model learned a decryption key specific to the diffuser property. Although training the model with data from multiple encryption keys seemed to allow it to learn the statistical information of all diffusers with enhanced scalability, it was preconditioned with the ballistic component that offered a physical meaning invariance among the speckle data. Additionally, the model scalability was enhanced with larger weight of ballistic light as the spatial coherence of output field can be stronger. Based on the above findings, the network generalization ability was enhanced in experiment by increasing the detected ballistic component.
A few more discussions about this paper were clarified herein. First, it seemed the previous DL works about scalable imaging through scattering media [23–26] did not differentiate the roles of scattered and ballistic light; thus, were not aware of the ballistic contribution as a precondition. Usually, it was not the case to have a purely diffuse system in experiment when the diffuser was at the focal plane of subsequent imaging optics. There did exist a part of ballistic light, which could be estimated by comparing the experimentally measured CCC curve with the simulated ones [Fig. 4(d)]. Second, in our paper, instead of using multiple diffusers, multiple regions of one diffuser were employed, which corresponded to different TMs, whereas, having the same mean scattering characteristics. Finally, in addition to revealing the prerequisite of ballistic light during one-to-all model training for better scalability, our paper also tried to define the physical boundary for a DL model trained under varying scattering conditions. It was hypothesized that the number of encryption keys involved during network training, resulting from internal or external perturbations, a change in incident beam, etc., cannot be unlimited. This may confuse a network due to the interference among the keys or even exceed its recognition capability. Besides, DL for scalable imaging through a thick scattering medium also saw limitation because of a lack of ballistic contribution. Enough data under each encryption key (corresponding to various scattering conditions) with an invariant correlation (i.e., ballistic component) among them, will define the boundary for the construction of a scalable DL model and further application. For example, a recent work for 3D adaptive descattering via a DSN [26] still relied on training data with sufficient ballistic component by detecting mostly the single-scattered photons in holographic particle imaging.
To summarize, our findings added new knowledge to the physical mechanisms of utilizing DL for scalable imaging through scattering media in which the roles of scattered and ballistic light components were revealed for contributing to the origin and physical boundary of the model adaptivity. The paper also offered practical guidance for improving the DL scalability by gating the ballistic photons. This can be performed by increasing the diffraction distance in our setup (also adopted for Refs. [19,25]) or introducing a spatial filter in a general setup [8,18,23] where the diffuser is imaged onto a camera via an objective lens or system. Nowadays, the one-to-all training strategy had become the mainstream way to increase network generalization. Herein, our research results deepened the cognition on this mainstream method and provided guiding significance for the related areas. It reminded us that the invariant correlation among the multisource speckle data was a perquisite for successful one-to-all training. Besides, the physical boundary of applying DL to descattering with general applicability was also defined to prescribe the scope of application. The mechanism understanding and guidance value of our research were beneficial for developing DL frameworks for scalable imaging under dynamic scattering scenarios.
Acknowledgment
Acknowledgment. H. L. conceived the idea and designed the experiment and simulation. X. Z., J. G., Y. G., and C. S. implemented the experiment and simulation. X. Z., S. C., P. L., and H. L. analyzed the data and wrote the paper. All contributed to revising the paper.
References
[2] J. Bertolotti, O. Katz. Imaging in complex media. Nat. Phys., 18, 1008-1017(2022).
[5] F. Helmchen, W. Denk. Deep tissue two-photon microscopy. Nat. Methods, 2, 932-940(2005).
[29] O. Ronneberger, P. Fischer, T. Brox. U-net: convolutional networks for biomedical image segmentation. 18th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 234-241(2015).

Set citation alerts for the article
Please enter your email address
© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20