Applications of ghost imaging are limited by the requirement on a large number of samplings. Based on the observation that the edge area contains more information thus requiring a larger number of samplings, we propose a feedback ghost imaging strategy to reduce the number of required samplings. The field of view is gradually concentrated onto the edge area, with the size of illumination speckles getting smaller. Experimentally, images of high quality and resolution are successfully reconstructed with much fewer samplings and linear algorithm.
Ghost imaging (GI) provides a way to obtain images with a single-pixel detector, employing second-order correlation between the illumination field and the signal from the object. Since the first realization with entangled photons[1–3], researchers made great developments in different aspects[4–14], showing its ability for lensless imaging[15] and robustness against noise[16,17], and exploring possible applications in different fields[18–24]. With the illumination patterns actively controlled and computed, the detector in the reference arm can be omitted, which further simplified the system into a real single-pixel imaging system. This is called computational GI[25–28]. Due to the feature of correlation, a large number of measurements are required to achieve high-quality images, which limits the performance of GI. Many methods[29–35] have been proposed towards this issue. Based on the sparsity of the interested scene, compressive GI (CSGI)[30,31] has been proved to be an effective method to decrease the number of required samplings, with the cost of heavy computing consumption. Then, adaptive GI methods based on compressed sensing and wavelet trees[31–33] were reported to slow down the growth of computing consumption over the size of the image. However, complicated data processing algorithms are still required, which also costs additional time after data sampling. Therefore, methods that can decrease both the number of required measurements and computation consumption are crucial for real-time imaging.
In conventional GI, every pixel within the illuminated scene is treated evenly, without considering how much information is required to properly describe it. Towards this, researchers performed GI in an adaptive way, by adjusting illumination patterns according to previous results[36–39]. As is observed, the edge areas of the objects contain the most details, and thus more information is required to clearly reconstruct the image of those areas. At the same time, the temporal–spatial distribution of speckles determines the information we can achieve from the target. If we divide the imaging process into different stages and gradually find out it and concentrate on the edge area, it is possible to improve effective information obtained via each measurement. Based on this idea, we propose a method named edge lit feedback GI (ELFGI) to adaptively adjust the field of view and the average size of speckles according to the previous images; thus, the illumination area providing higher spatial resolution is gradually concentrated onto the edge area. The image of the scene is gradually becoming distinct, while the number of required samplings is greatly reduced compared to conventional GI. Data processing is performed along with data acquisition, using a linear algorithm.
2. The Scheme
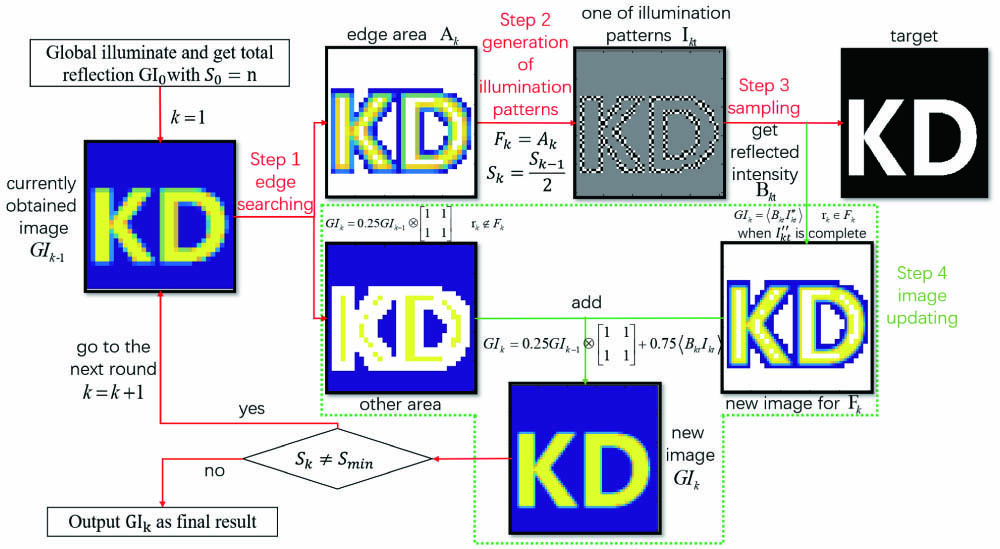
In a typical GI system, a sequence of patterns are illuminated onto the object, with the counterpart echoes from the object detected with the bucket detector; then the correlation between these patterns and the detection results provides the image. In our scheme, the sequence of patterns is adaptively arranged. According to different settings of the illumination patterns, the whole imaging process is divided into many rounds. For each round, four steps are performed, namely, edge searching, pattern generation, sampling, and image updating. Firstly, we consider binary sparse objects for convenience. The scene is described as , with the size of . We use to denote the field of view, and to denote the size of speckles in the th round. In every round, an image of size is reconstructed. Here, is the coordinate in the image, and the resolution is . Every value in actually shows the total reflection within the block with the size of . is then used as the input of the next round. A flow diagram is shown in Fig. 1. To start, we light up the whole scene and measure the reflected intensity of the target as , the resolution of which is . Then, the imaging process moves forward to the rounds containing the following four steps.
Sign up for Chinese Optics Letters TOC. Get the latest issue of Chinese Optics Letters delivered right to you!Sign up now
Figure 1.Schematic diagram of feedback GI. The picture shows the flow diagram of ELFGI, which is divided into four steps. The arrows show the direction of the steps and data. The red arrow of Step 3 also shows that the illumination patterns are lighted onto the target.
Step 1: edge searching. For binary targets, the grayscale values within the object (background) areas are close to the maximum (minimum), with noise involved. If these areas are picked out, the rest of the area is the edge area. Considering white Gaussian noise in bucket detection with the standard deviation , the standard deviation of the error in every pixel of the currently obtained image is , with being the total number of performed measurements. Considering the errors, we can pick out the edge areas , which are defined as the set of , which satisfies Here, actually defines the tolerance of errors, and is set as a constant, since can be taken as unchanged during each experiment. In practice, can be estimated from the fluctuation of the bucket detection under the same illumination, and is set as . Higher promises higher confidence that the selected part belongs to the edge area.
Step 2: generation of illumination patterns. Since the image obtained in each round is used as the input of the next round, the quality of the image will be important for edge searching. GI with Hadamard patterns[40,41] provides an image of high accuracy with complete samplings. Therefore, we use the Hadamard matrix as the basic pattern, with each row of the matrix being one frame of the illumination pattern, and perform complete samplings for each round to achieve an image of as high quality as possible. Since the size of speckles is large when the field of view is large, and the field of view is concentrated to the edge area when the size of speckles becomes small, a large number of frames are not required, as will be shown later. Each element in corresponds to the reflection of a block with the size of . is also constituted with such blocks. To obtain more details about the edge area, the resolution should be improved, which means the speckles in the new masks should be smaller than those of the previous rounds. Each block in with the size of is divided evenly into four squares, with every square being a new block in this round. The size of the blocks is with the coordinates updated into . When used to generate the masks, each element of the Hadamard matrix describes the intensity of the counterpart block in the mask. As defined, the number of elements in each mask is . To match the illumination area with the determined edge area , we set , where is the number of blocks contained in . That is, we set the illumination matrix to be the smallest Hadamard matrix that can cover the edge area, and every block in is a speckle in . As the number of speckles in is , a Hadamard matrix of can be used to generate the masks, according to the recursion relationship[41]: where is the Hadamard matrix of , and contains rows of , respectively. here represents the operation of the Kronecker product. In traditional Hadamard GI, each row of is reshaped into an illumination mask . Since the measurement matrix is equivalent to , which represents those patterns of the last round with being the imaging result, only the parts containing , , and are necessary in the current round, with each row reshaped into an illumination mask .
Step 3: sampling. determined in the previous step are the expected masks, which contain negative values. In practice, the values of in are changed into zero, as Here, is the actually performed illumination. Then, the reflected intensity is measured and written as Therefore, corresponding to the expected illumination can be obtained as where we use to replace within , as is actually the measured reflection of the target from previous rounds, while is the real reflection.
Step 4: image updating. The new image is constituted by two parts, the area in and out of . For the area in , as corresponds to the whole . , with the size expanded, is used to take the role of , which occupies one quarter of in our method. Thus, can be reconstructed with
For the area out of , the value on each pixel of equals one quarter of at the same position, due to the size changing of speckles. Since , Eq. (6) also works for the region out of , from which the image is updated for the whole scene.
After Step 4, if has reached the limit of the imaging system, the whole imaging process is finished, and is taken as the final result; otherwise, move to Step 1 for the next round.
3. Experiments and Results
To implement our method, we build a very simple setup, as shown in Fig. 2. A commercial projector (Panasonic PT-X301) is employed as the source, which outputs different masks with pixels, controlled by a laptop. The size of each pixel is 0.24 mm × 0.24 mm on the object plane, which is 45 cm away from the output lens of the projector. The reflected light by the target is collected with a lens and detected by a CCD camera. For each frame, the values on all pixels of the camera are summed up and quantified to 0–255 as the bucket detection. Data acquisition and data processing are performed simultaneously. After each round, the edge area is picked out with the laptop, and then new illumination patterns for the next round are generated, which will be imprinted on the object plane to update the image.
Figure 2.Experimental setup. The illumination patterns are generated via a laptop (not shown), which controls the emission of a commercial projector. The reflected light from the object is collected with a lens and detected with a CCD camera with the results on all the pixels summed up as a bucket detector.
The objects used in our experiments are made by cutting a piece of paper into Chinese characters, as shown in Figs. 3(a1) and 3(c1). The images retrieved in the 4th–7th rounds with ELFGI are shown in Figs. 3(b1)–3(b4) and 3(d1)–3(d4). The reconstructed images become distinguishable after four rounds, clearer and clearer. The edge area, which is also the field of view, is getting smaller and smaller. The number of pixels illuminated in the 4th–7th rounds is 16,384, 8192, 8192, and 4096, respectively. The resolution is increased as average sizes of the speckles at the 4th–7th round are 16, 8, 4, and 2 pixels, with the corresponding number of speckles within the illumination area being 64, 128, 512, and 1024, respectively. The total number of performed illumination patterns is 70, 166, 550, and 1318, respectively. The images shown in Figs. 3(a2)–3(a4) and 3(c2)–3(c4) are the results of conventional GI with 2000 frames using random speckles, and the average sizes of the speckles are 16, 4, and 2 pixels, respectively. It can be seen that the images retrieved with our method appear to be with higher quality than that of conventional GI. To quantitatively compare those results, the mean square error (MSE) is considered, defined as . The reference is obtained with traditional imaging. The results via ELFGI become clear fast when MSE drops sharply. The result is very close to the target after seven rounds, with the MSE being 0.0075. With the same number of measurements, the MSEs of conventional GI are 0.24, 0.11, and 0.041 when the average sizes of speckles are 16, 4, and 1 pixel(s). From these results, it is verified that our method helps get an image of higher quality with fewer samplings with a simple retrieving algorithm. Thus, the process of GI can be accelerated with our method.
Figure 3.Experimental results for two targets shown in (a1) and (c1). (a2)–(a4) and (c2)–(c4) show imaging results via GI using random speckles, with the size of speckles being 16, 4, and 2 pixels, respectively. The number of measurements is 2000. (b1)–(b4) and (d1)–(d4) show results of ELFGI with T obtained at the 4th–7th round, costing 70, 166, 550, 1318 and 43, 139, 523, 1291 frames, respectively.
Figure 4.Simulation results. (a1) is the target for resolution test, with the width of the narrowest stripes being 1 pixel. (a2) shows results of ELFGI with T, (a3) is obtained via GI with random speckles, and (a4) shows results of GI with Hadamard patterns. The number of samplings is 4480, 47,104, and 65,536, respectively. (b1) is a grayscale target of three-level values. (b2)–(b4) are the results of ELFGI with T, obtained in the 4th, 6th, and 8th rounds under 256, 1408, and 6016 samplings.
Actually, our method also provides a way to remove the trade-off between high resolution and high signal-to-noise ratio (SNR)[42], both of which require a large number of samplings. To demonstrate this, we do simulations for the chart with objects of different sizes, as shown in Fig. 4(a1). Results from different methods are shown in Figs. 4(a2)–4(a4). It takes 65,536 samplings for GI with Hadamard patterns. For conventional GI with random speckles, the narrowest stripes are still barely visible with 47,104 samplings. With our method, fewer samplings (4480) are required to achieve the expected resolution. Therefore, the requirement on a high number of samplings for high resolution is greatly reduced.
Our method can also work for grayscale objects, with the algorithm of edge searching adapted. We simulate imaging an object of three-level grayscale values, as shown in Fig. 4(b1). To find out the edge area, the Canny operator algorithm is used. The imaging results are shown in Figs. 4(b2)–4(b4). With eight rounds and 6016 samplings in total, an image of is perfectly retrieved. That is, our method has the capacity to reconstruct grayscale images with the number of required samplings reduced.
The performance of our method under noise is also explored with simulations, with the results shown in Fig. 5. The SNR of the bucket detection, defined as the ratio between the average value of the bucket detection and the standard deviation of noise, is used to measure the influence of noise. The amount of required samplings is proportional to for traditional GI to get the image of certain quality. As for ELFGI, we change according to the noise and repeat measurements in the first five rounds to increase reliability of the measurement. Although a decline in the quality is unavoidable, the image is distinguishable using ELFGI or CSGI. From the results, with a comparable number of measurements, the imaging quality of CSGI is a little better than of ELFGI. However, the time cost for extra calculation in CSGI (90 s for 4500 samplings using a laptop with CPU of E5-2667 at 3.30 GHz) is hundreds of times longer than that of ELFGI (0.39 s). The algorithm of CSGI used here is a gradient projection for sparse reconstruction.
Figure 5.Simulation results under different noise with different methods. The amount of samplings is 16,384, 65,536, 262,144, and 1,048,576 for traditional GI and 5829, 10,528, 17,984, and 21,056 for ELFGI with T = 0, 76, 152, 304, respectively. As for CSGI, it costs 6000, 8000, 16,000, and 20,000 samplings.
Experimentally, we are using a commercial projector, which makes the experiments easier to perform. Such projectors are usually not fast enough for real-time imaging. By modulating a laser with a digital micro-mirror device (DMD) or a spatial light modulator (SLM), the refresh rate of the source can be improved. Then, the sampling rate and the minimum resolution of GI can be improved. The time consumption of the calculation can also be reduced by hardware design. Therefore, our method makes GI closer to practical applications, since fewer samplings are required. Although we employed Hadamard illumination patterns in our discussion and experiments, the design and selection of illumination patterns are not confined. The key of our method is to gradually find out the edge area and adaptively adjust the field of view as well as the size of speckles. Besides, it is also possible to obtain the edge area using existing methods based on GI [43,44] and concentrate the illumination patterns accordingly.
4. Conclusion
In conclusion, based on the observation that the edge area requires more information and thus more samplings, we proposed and demonstrated a feedback strategy for GI. In this method, the edge area is determined from previous images, and then the illumination patterns with smaller speckles are concentrated onto the edge area. Thus, more details about the edge will be extracted, while the number of samplings does not increase much since the field of view is reduced. The experimental results show that our method helps to speed up the process of GI. Images of high quality can be reconstructed from a greatly reduced number of samplings, compared to conventional GI. This method can be very helpful for medical imaging, since low sampling number requirement means low photon flux and thus less radiation injury.
[10] D. Z. Cao, J. Xiong, S. H. Zhang, L. F. Lin, L. Gao, K. Wang. Enhancing visibility and resolution in Nth-order intensity correlation of thermal light. Appl. Phys. Lett., 92, 013802(2008).