Training an artificial neural network with backpropagation algorithms to perform advanced machine learning tasks requires an extensive computational process. This paper proposes to implement the backpropagation algorithm optically for in situ training of both linear and nonlinear diffractive optical neural networks, which enables the acceleration of training speed and improvement in energy efficiency on core computing modules. We demonstrate that the gradient of a loss function with respect to the weights of diffractive layers can be accurately calculated by measuring the forward and backward propagated optical fields based on light reciprocity and phase conjunction principles. The diffractive modulation weights are updated by programming a high-speed spatial light modulator to minimize the error between prediction and target output and perform inference tasks at the speed of light. We numerically validate the effectiveness of our approach on simulated networks for various applications. The proposed in situ optical learning architecture achieves accuracy comparable to in silico training with an electronic computer on the tasks of object classification and matrix-vector multiplication, which further allows the diffractive optical neural network to adapt to system imperfections. Also, the self-adaptive property of our approach facilitates the novel application of the network for all-optical imaging through scattering media. The proposed approach paves the way for robust implementation of large-scale diffractive neural networks to perform distinctive tasks all-optically.
1. INTRODUCTION
Artificial neural networks (ANNs) have achieved significant success in performing various machine learning tasks [1], diverse from computer science applications (e.g., image classification [2], speech recognition [3], game playing [4]) to scientific research (e.g., medical diagnostics [5], intelligent imaging [6], behavioral neuroscience [7]). The explosive growth of machine learning is due primarily to the recent advancements in neural network architectures and hardware computing platforms, which enable us to train larger-scale and more complicated models [8,9]. A significant amount of effort has been spent on constructing different application-specific ANN architectures with semiconductor electronics [10,11], the performance of which is inherently limited by the fundamental tradeoff between energy efficiency and computing power in electronic computing [12]. As the scale of an electronic transistor approaches its physical limit, it is necessary to investigate and develop the next-generation computing modality during the post-Moore’s law era [13,14]. Using photons instead of electrons as the information carrier to perform optical computing has potential properties to provide high energy efficiency, low crosstalk, light-speed processing, and massive parallelism. It has the potential to overcome problems inherent in electronics and is considered to be the disruptive technology for modern computing [15,16].
Recent works on the optical neural network (ONN) have made substantial progress in performing large-scale complex computing and high optical integrability by using state-of-the-art intelligent design approaches and fabrication techniques [17–19]. Various ONN architectures have been proposed, including the optical interference neural network [20,21], diffractive optical neural network [22,23], photonic reservoir computing [24,25], photonic spiking neural network [26–30], optical recurrent neural network [31,32], etc. Among them, constructing diffractive networks with diverse diffractive optical elements provides an extremely high degree of freedom to train the model and facilitates important applications in a wide range of fields, such as object classification [22,33–38], segmentation [23], pulse engineering [39], and depth sensing [40]. It has been demonstrated that the all-optical machine learning framework using diffractive ONN [22,23], i.e., diffractive deep neural networks (D2NNs), can successfully classify the Modified National Institute of Standards and Technology (MNIST) handwritten digits dataset [41] with classification accuracy quite approaching electronic computing. These diffractive ONN models are physically fabricated with 3D printing or lithography for different inference tasks, where the network parameters are fixed once the network is created. The approach proposed in this paper adopts the cascading of spatial light modulators (SLMs) as the diffractive modulation layers, which can be programmed to train different network models for different tasks.
Proper training of the ANN with algorithms, such as error backpropagation [41], is the most critical aspect of making a reliable model and guarantees accurate network inference. Current ONN architectures are typically trained in silico on an electronic computer to obtain its designs for physical implementation. By modeling the light–matter interaction along with computer-aided intelligent design, the network parameters are learned, and the structure is determined to be deployed on photonic devices. However, due to the high computational complexity of the network training, such in silico training approaches fail to exploit the speed, efficiency, and massive parallel advantage of optical computing, which results in long training time and limited scalability. For example, it takes approximately 8 h to train a five-layer diffractive ONN configured with 0.2 million neurons as a digit classifier running on a high-end modern desktop computer [22]. Furthermore, different error sources in practical implementation will deviate the in silico trained model and degenerate inference accuracy. In situ training, in contrast, can overcome these limitations by physically implementing the training process directly inside the optical system. Recent works have demonstrated the success of in situ backpropagation for training the optical interference neural network [42] and physical recurrent neural network [43,44]. Nevertheless, these approaches either require strict lossless assumptions for calculating the time-reversed adjoint field or work only for a real-valued network by modeling the amplitude of the field, which cannot be applied to the diffractive ONN due to the complex-valued inherency and the presenting of diffractive loss. Another line of work based on the volumetric hologram [45,46] requires an undesirable light beam in the hologram recording and size-1 training batch, which dramatically restricts the network scalability and computational complexity. In this work, we propose an approach for in situ training of the large-scale diffractive ONN for complex inference tasks that can overcome the lossless assumption by modeling and measuring the forward and backward propagations of the diffractive optical field for its gradient calculation.
Sign up for Photonics Research TOC. Get the latest issue of Photonics Research delivered right to you!Sign up now
The proposed optical error backpropagation for in situ training of the diffractive ONN is based on light reciprocity and phase conjunction principles, which allow the optical backpropagation of the network residual errors by backward propagating the error optical field. We demonstrate that the gradient of the network at individual diffractive layers can be successively calculated highly parallel to measurements of the forward and backward propagated optical fields. We design a reprogrammable system with off-the-shelf photonic equipment by simulation for implementing the proposed in situ optical training, where phase-shifting digital holography is used for optical field measurement, and the error optical field is generated from a complex field generation module. Different from in silico training, by programming the multilayer SLMs for iteratively updating the network diffractive modulation coefficients during training, the proposed optical learning architecture can adapt to system imperfections, accelerate the training speed, and improve the training energy efficiency on core computing modules. Also, diffractive ONNs implemented with multilayer SLMs can be easily reconfigured to perform different inference tasks at the speed of light. The numerical simulations on the proposed reconfigurable diffractive ONN system demonstrate the high accuracy of our in situ optical training method for different applications, including light-speed object classification, optical matrix-vector multiplier, and all-optical imaging through scattering media.
2. OPTICAL ERROR BACKPROPAGATION
The diffractive ONN framework proposed in Ref. [22] comprises the cascading of multiple diffractive modulation layers, as shown in Fig. 1(a), where an artificial neuron on each layer modulates the amplitude and phase of its input optical field and generates a secondary wave through optical diffraction for connecting to other neurons of the following layers. The modulation coefficients of neurons are iteratively updated during the training that tunes the network towards a specific task. Despite that the network configurations in Ref. [22] for proof-of-concept experiments adopt only the linear diffractive optical neuron for processing a complex optical field, the detector on the output plane of the network measures its intensity (square of the amplitude) distribution, which performs the activation function of the diffractive computing result. Also, the optical nonlinearity can be incorporated to achieve the activation function for neurons at individual layers [23] that can accomplish more complicated inference tasks. Instead of training in an electronic computer and fabricating with 3D printing, we propose to implement the phase-only diffractive modulation layers with the phase SLM, e.g., liquid crystal on silicon (LCOS), which can be programmed to update network weights and enables in situ training of both linear [22] and nonlinear [23] diffractive ONNs.
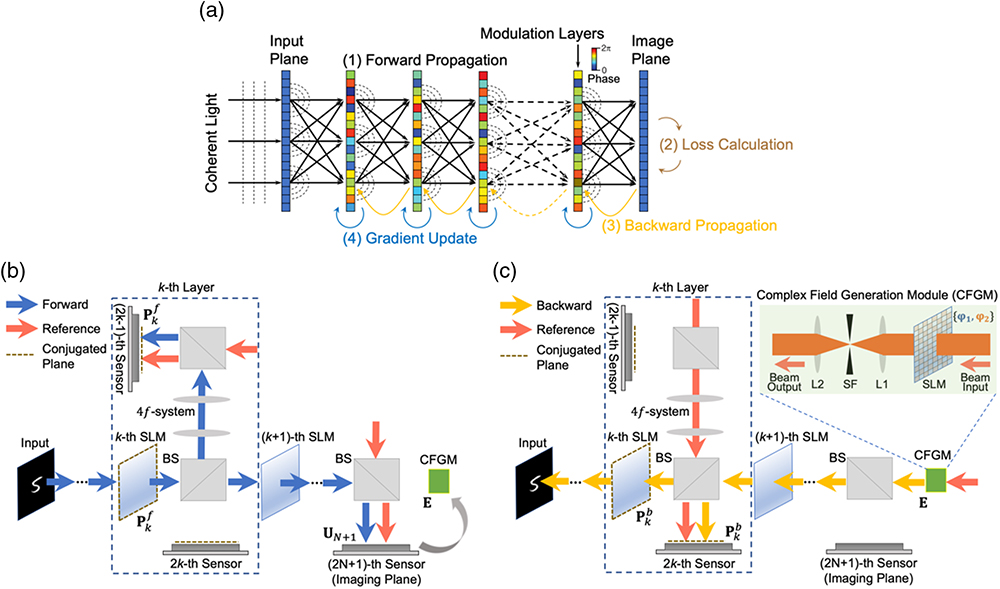
Figure 1.Optical training of diffractive ONN. (a) The diffractive ONN architecture is physically implemented by cascading spatial light modulators (SLMs), which can be programmed for tuning diffractive coefficients of the network towards a specific task. The programmable capability makes it possible for in situ optical training of diffractive ONNs with error backpropagation algorithms. Each iteration of the training for updating the phase modulation coefficients of diffractive layers includes four steps: forward propagation, error calculation, backward propagation, and gradient update. (b) The forward propagated optical field is modulated by the phase coefficients of multilayer SLMs and measured by the image sensors with phase-shifted reference beams at the output image plane as well as at the individual layers. The image sensor is set to be conjugated to the diffractive layer relayed by a 1:1 beam splitter (BS) and a system. (c) The backward propagated optical field is formed by propagating the error optical field from the output image plane back to the input plane with the modulation of multilayer SLMs. The error optical field is generated from the complex field generation module (CFGM) by calculating the residual errors between the network output optical field and the ground truth label. With the measured forward and backward propagated optical fields, the gradients of the diffractive layers are calculated, and the modulation coefficients of SLMs are successively updated from the last to first layer.
In this section, we derive the optical error backpropagation model for linear diffractive ONN, and its extension to the nonlinear diffractive ONN can be found in Section 6 of Appendix A. To implement the error backpropagation optically, we build the in situ training optimization model and demonstrate that the gradient of the loss function of diffractive ONNs can be calculated by measuring the forward propagated input optical field and backward propagated error optical field. The forward propagation model of the diffractive ONN in Fig. 1(a) can be established based on the Rayleigh–Sommerfeld diffraction principle [22], where the complex transform of the optical field between successive diffractive modulation layers can be formulated as where represents the vectorized output optical field of a -th layer of the network; is the diffractive weight matrix with the forward light propagation from the -th to the -th layer; and represents the diagonalization of a vectorized diffractive modulation at the -th layer with a phase coefficient of , with being the imaginary unit, i.e., . Under coherent illumination, the optical field of an object at the input layer propagates through multiple diffractive optical layers and generates the optical field of the output layer of the network at the imaging plane: where we assume that the diffractive ONN is composed of layers excluding the input and output layers. The detector at the imaging plane measures the intensity distribution of the resulting optical field and obtains the network inference result: The in situ optical training of the network involves successively updating phase coefficients of diffractive layers with the calculated gradient to minimize a loss function. Let represent the loss function of diffractive ONN that measures the differentials between network outputs and ground truth labels . The gradient of the defined loss function with respect to the phase modulation coefficient of a -th layer can be derived as where represents element-wise multiplication, and means conjugation of the optical field. The gradient of with respect to the can be derived as where diag represents the diagonalization operation. Substituting Eq. (5) into Eq. (4) and letting denote the error optical field, we have where The underlying physical meaning of is the output optical field of a -th layer by propagating the optical field of an object from the input layer to layer . According to the reciprocity principle of light propagation [44], represents the diffractive weight matrix between the -th layer and the -th layer with backward light propagation in the opposite direction of . Therefore, is the optical field corresponding to the backward propagation of the error optical field from the output plane of the network to the -th layer. The error optical field comprises the multiplication of two terms, i.e., and . represents the gradient of the loss function with respect to output intensity , where we use the mean squared error as the loss function, i.e., , where is the norm, with which . represents the conjugation of the network output optical field that ensures the success of backpropagating the residual error optically according to the phase conjunction technique [42]. By measuring the forward and backward propagated optical fields and at the -th layer, the gradient of the loss function with respect to the phase coefficient of the -th layer can be efficiently calculated based on Eq. (7).
As shown in Fig. 1(a), the proposed in situ optical training procedure for measuring the gradient of a diffractive layer in the network can be summarized as follows: (1) measuring the forward optical field at the network output layer and the -th layer by forward propagating the input optical field through diffractive modulation layers to the output image plane; (2) calculating the error optical field with the network output optical field and the ground truth label; (3) measuring the backward optical field at the -th layer by backward propagating the error optical field from the output imaging plane through diffractive modulation layers to the input object plane; (4) calculating the gradient of the current layer with the measured forward and backward optical fields. During each iteration of the training, given an input–output example, the network phase modulation coefficients are updated with the calculated gradient by the chain rule that backward adjusts one layer at a time from the last layer to the first layer. The pseudo-code of the proposed optical error backpropagation algorithm can be found in Section 1 of Appendix A. In the next section, we demonstrate the system design to implement the abovementioned in situ optical training procedure for diffractive ONN with off-the-shelf photonic equipment.
3. EXPERIMENTAL SYSTEM DESIGN AND CONFIGURATION
We propose an optical system design composed of off-the-shelf photonic equipment to implement the optical error backpropagation for in situ training of diffractive ONN, as shown in Figs. 1(b) and 1(c). The proposed system configuration adopts multilayer programmable SLMs as the diffractive modulator for high-speed updating of network coefficients during the training towards performing distinct inference tasks. To measure the forward and backward propagated optical field at the individual modulation layer, we adopt a pair of image sensors and conjugate their sensor planes to the SLM modulation plane in the forward and backward optical paths, respectively. Conjugation of the planes is achieved by using a beam splitter (BS) and a system. Different transmission rates of BS can be applied by multiplying constant coefficients during the gradient update. We use the 1:1 BS in this implementation for the sake of simplicity. Since the image sensor can measure only the intensity distribution of an optical field, we adopt the phase-shifting digital holography approach [47] to measure the interference of the forward and backward optical fields with the phase-shifted reference beam to obtain the network optical field effectively. The output optical field of the network is simultaneously measured for calculating the error optical field given the inputs and ground truth labels, which is used to propagate the residual errors backward and minimize a loss function by iteratively updating the phase modulation coefficients of SLMs. We show that the error optical field can be generated by an interleaving of two complementary phase modulation patterns with low-pass filtering, which can be physically implemented with an SLM and a system. In the following, we detail the measurement and generation of the complex optical field for the network gradient calculation.
A. Measuring the Network Optical Field
We adopted four-step phase-shifting digital holography [47] to measure the optical field at individual layers. Assume represents the forward propagated optical field or the backward propagated optical field at the -th layer, where refers to its amplitude, and refers to its phase. The network optical field was interfered with a four-step phase-shifted reference beam , i.e., the phase value of the wavefront , where is the amplitude with a constant value. The corresponding intensity distributions of the interference results were sequentially measured with an image sensor, with which the amplitude and phase of the optical field at the -th layer can be accurately calculated as where is a constant value.
B. Generating the Error Optical Field
The error optical field was generated with a complex field generation module (CFGM) that acts as the source of a backward propagated optical field. In this paper, we implemented it with a phase-only field generator SLM and a low-pass filtering system [48], as shown in Fig. 1(c). The field generator SLM was set to be conjugated to the imaging plane in order to backpropagate the residual error between network output fields and ground truth labels for updating the network weights. To generate the complex optical field with a phase-only SLM, the error optical field, i.e., , was decomposed into two optical fields with a constant amplitude, i.e., , so that two phase patterns and can be interleaved multiplexed on the SLM. Let and represent a pair of a complementary pixel-wise binary checkerboard pattern, i.e., , and then the multiplexed phase pattern for the SLM can be formulated as , where represents the nearest-neighbor spatial upsampling of two phase patterns. Since the zero order of the spectrum of the optical field generated by the multiplexed pattern is the desired error optical field, a spatial low-pass filter was placed at the Fourier plane of a system to filter out the undesired high-order diffraction spectra. We further performed the nearest-neighbor upsampling ( in this paper) on the multiplexed pattern to achieve a broader spectrum separation and reduce the spectral aliasing in the generated error optical field.
With the proposed system design to measure the forward propagated input optical field and backward propagated error optical field for in situ training of the network, the gradient at each diffractive layer is successively calculated, and the phase coefficients of SLMs are iteratively updated by adding the phase increment , where is a constant network parameter determining the learning rate of the training. Since there are constant scale factors during the measurement of the network optical field and the generation of the error optical field, i.e., and , respectively, we tune the value of during the training so that the phase coefficients are updated at an appropriate step size. Different from the brute force in situ training approach [20] that computes the gradient of ONNs by sequentially perturbing the coefficient of individual neurons, the optical error backpropagation approach proposed in this paper allows for tuning the network coefficients in parallel. This enables us to effectively train the large-scale network coefficients and significantly enhances the scalability of the diffractive ONN. Furthermore, since our framework directly measures the optical field of a network at individual layers, it avoids performing the interference between the forward and backward optical fields and eliminates the assumption of losslessness used in Ref. [42]. This is important for the optical training of diffractive ONNs because of the inherent diffraction loss on the network periphery caused by freespace light propagation.
4. NUMERICAL SIMULATIONS AND APPLICATIONS
In this section, we numerically validate the effectiveness of the proposed optical error backpropagation and demonstrate the success of in situ optical training of simulated diffractive ONNs for different applications, including light-speed object classification, optical matrix-vector multiplication, and all-optical imaging through scattering media.
A. Light-Speed Object Classification
Object classification is a critical task in computer vision and is also one of the most successful applications of ANNs. The conventional object classification paradigm typically requires to capture and store large-scale scene information as an image by using an optoelectronic sensor and compute with artificial intelligence algorithms in an electronic computer. Such a storage and computing separation paradigm places significant limitation on the processing speed. Our all-optical machine learning framework based on diffractive ONNs performs the light-speed computing directly on the object optical wavefront so that the detectors need to measure only the classification result, e.g., 10 measurements for 10 classes on the MNIST dataset, as shown in Fig. 2(a). This dramatically reduces the number of measurements and enhances the classification response speed. The proposed in situ optical training in this paper allows for the robust implementation of diffractive ONNs and enables the reconfigurable capability by using programmable diffractive layers.
Figure 2.In situ optical training of the diffractive ONN for object classification on the MNIST dataset. (a) By in situ dynamically adjusting the network coefficients with programmable diffractive layers, the diffractive ONN is optically trained with the MNIST dataset to perform object classification of the handwritten digits. (b) The numerical simulations on 10-layer diffractive ONN show the blind testing classification accuracy of 92.19% and 91.96% for the proposed in situ optical training approach without and with the CFGM error, respectively, which achieves a performance comparable to the electronic training approach (classification accuracy of 92.28%). (c) After the optical training (with CFGM error), phase modulation patterns on 10 different diffractive layers () are shown, which are fixed during the inference for performing the classification at the speed of light. (d) The visualization of the network gradient reveals that the proposed optical error backpropagation accurately obtains the network gradient with accuracy comparable to the electronic training by calculating the differential between the electronic and optical gradients of the diffractive layer one at first iteration. Scale bar: 1 mm.
The effectiveness of the proposed approach was validated by comparing the performance between in situ optical training and in silico electronic training [22] of a 10-layer diffractive ONN (see Section 2 and Fig. 5 of Appendix A for classification performance w.r.t. the layer number) for classifying the MNIST dataset under the same network settings. The object can be encoded into different properties of the optical field, e.g., amplitude, phase, and wavelength. In this work, the diffractive ONNs were set to work under a coherent illumination at the SLM working wavelength of 698 nm (e.g., with CNI MRL-FN-698 laser source), and the input objects were encoded by using the amplitude of the optical field. Considering the practical implementation of the in situ optical training system, the pixel pitch of the SLM was set to 8 μm, e.g., with the Holoeye PLUTO-2 phase-only SLM. Since the CFGM module requires nearest-neighbor spatial upsampling to reduce the spectrum aliasing, the neuron size was set to 32 μm by binning SLM pixels. For the classification diffractive ONN, the network was configured with 10 diffractive modulation layers by packing neurons on each layer, covering an area of per layer on the SLM. The successive layer distance was optimized with grid search within the range of 0–50 cm and set to 20 cm. The MNIST handwritten digit () dataset has 55,000 training images, 5000 validation images, and 10,000 testing images with each image size of . The image size was upsampled four times with boundary padding to match the network size. To satisfy the boundary condition of freespace propagation numerically implemented with the angular spectrum method [22], the network periphery was further padded with a length of 0.8 mm. The classification criterion is to find the detector with the maximum optical signal among 10 detector regions (corresponding to 10 digits), where each detector width is set to 1.6 mm. This was also used as a loss function during network training. We used the stochastic gradient descent algorithm (Adam optimizer) [22] for the in silico electronic training; the in situ optical training was numerically implemented with the proposed optical error backpropagation algorithm. Both in silico electronic training and in situ optical training were implemented on the platform of Python version 3.6.7 with TensorFlow framework version 1.12.0 (Google Inc.) using a desktop computer (Nvidia TITAN XP Graphical Processing Unit, GPU, and Intel Xeon Gold 6126 CPU at 2.60 GHz with 64 cores, 128 GB of RAM, running with a Microsoft Windows 10 operating system).
The convergence plots of in silico electronic and in situ optical training of 10-layer diffractive ONN by using the MNIST training dataset and evaluating on the validation dataset are shown in Fig. 2(b). The optical training was assessed with and without incorporating the errors from the CFGM, which was caused by the spectrum aliasing in generating the error optical field. With the learning rate setting of 0.01 and batch size setting of 10 for both electronic and optical training, the electronic training converged after 15 epochs of iteration, and the optical training converged after 16 epochs and 24 epochs without and with the CFGM errors, respectively. For the in situ optical training, the training instances in each batch are sequentially fed into the system during implementation. Also, the phase value of each neuron was wrapped to the range between 0 and in order to meet the modulation range of the SLM. The phase modulation layers of optical training with CFGM errors were converged to the patterns, as shown in Fig. 2(c), and the trained model was blind tested with the MNIST testing dataset. The numerical simulation results show that the proposed in situ optical training method achieves comparable performance with respect to the electronic training, i.e., blind testing accuracy of 92.19% and 91.96% for the optical training without and with the CFGM errors, respectively, compared with the blind testing accuracy of 92.28% for electronic training. To further demonstrate the accuracy of the network gradient during the in situ optical training, we compared and calculated the differential between the electronic and optical gradient of diffractive layer one at first iteration, as shown in Fig. 2(d). The differentials without and with CFGM error are six and approximately two orders of magnitude lower than the calculated gradient, respectively, which indicates that the proposed optical error propagation can accurately calculate the network gradient under the lossy condition. Despite that the CFGM error incorporates the stochastic noise to the gradient update that slows down the convergence speed and slightly decreases the classification accuracy, the proposed in situ optical training approach can adapt to its error as well as other system imperfections and successfully performs the object classification on the MNIST dataset.
B. Optical Matrix-Vector Multiplication
Matrix-vector multiplication is one of the fundamental operations in artificial neural networks, which is the most time- and energy-consuming component implemented with electronic computing platforms due to the use of a limited clock rate and large numbers of data movement. The intrinsic parallelism of optical computing allows large-scale matrix multiplication to be implemented at the speed of light with high energy efficiency without the use of the system clock or data movement. Previous works [20,49] on optical matrix-vector multiplication have limited degrees of freedom for constructing the matrix operator and required solving an optimization problem in electronic computers to derive the design before deploying with photonic equipment. Our in situ optical training approach eliminates the requirement for electronic optimization and has a much higher degree of freedom to achieve the desired matrix operator, which not only improves the optimization efficiency but also enhances the scalability of the operation.
The computational architecture of in situ optical training of diffractive ONN for matrix-vector multiplication is shown in Fig. 3(a). The elements of the input vector are encoded into different regions at the input plane, the values of which are represented by the amplitude of input optical fields. Correspondingly, the elements of the output vector are encoded into different regions at the output plane of the network and are measured as the detector intensity. Given an arbitrary matrix operator , we demonstrate that the reconfigurable diffractive ONN can be optically trained as the desired matrix-vector multiplier, i.e., , with high accuracy. For demonstration, we used the proposed optical error propagation framework to train a four-layer diffractive ONN to perform a matrix operation, i.e., ; the element values of a target matrix are shown in the last column of Fig. 3(c). For the in situ optical training of the matrix-vector multiplier network, we changed the neuron number on each layer to (covering an area of ) and the detector width to 0.64 mm, while keeping other network settings the same as that in light-speed object classification. We used the target matrix operator to generate input–output vector pairs as the training, validation, and testing datasets. The trained model performance with respect to the size of the training dataset can be found in Fig. 6 of Appendix A. To guarantee the model accuracy and minimize the computational resource of data generation, the training dataset was generated with 500 input–output vector pairs. Increasing the training set size can further improve model accuracy. Both validation and testing datasets were generated with 1000 input–output vector pairs for sufficiently evaluating the generalization of the network. The input vectors of the dataset were randomly sampled with a uniform distribution between zero and one. The optical training process converged after 30,000 iterations (60 epochs) under CFGM errors, and the trained diffractive modulation patterns are shown in Fig. 3(b). Figure 3(c) shows that the trained matrix-vector multiplier diffractive ONN successfully generated the output vector (third column) with accuracy comparable to the ground truth vector (second column) by taking the exemplar vector from the testing dataset as an input (first column). Different element values of the output vector were obtained by averaging the intensity of different detector regions [Fig. 3(d)]. The relative error, calculated as , was used to quantitatively evaluate the accuracy of the output vector with respect to the ground truth vector , which was found to be 1.15% on the exemplar vector and 1.37% over the testing vectors. We further demonstrate in Fig. 3(e) that increasing the number of diffractive modulation layers, e.g., from two layers to four layers, allows training the network with a higher degree of freedom, which significantly reduces the relative error of the output vector and improves the accuracy of the in situ optically trained diffractive ONN for performing the optical matrix-vector multiplication.
Figure 3.In situ optical training of the diffractive ONN as an optical matrix-vector multiplier. (a) By encoding the input and output vectors to the input and output planes of the network, respectively, the diffractive ONN can be optically trained as a matrix-vector multiplier to perform an arbitrary matrix operation. (b) A four-layer diffractive ONN is trained as a matrix operator [shown in the last column of (c)], the phase modulation patterns () of which are shown and can be reconfigured to achieve different matrices by programming the SLM modulations. (c) With an exemplar input vector on the input plane of the trained network (first column), the network outputs the matrix-vector multiplication result (second column), which achieves comparable results with respect to the ground truth (third column). (d) The relative error between the network output vector and ground truth vector is 1.15%, showing the high accuracy of our optical matrix-vector architecture. (e) By increasing the number of modulation layers, the relative error is decreased, and matrix multiplier accuracy can be further improved. Scale bar: 1 mm.
Imaging through scattering media has been one of the difficult challenges with essential applications in many fields [50–52]. Previous approaches typically performed object reconstruction in an electronic computer with the captured speckle intensity measurements, which use only limited input information due to missing the optical phase and hinder instantaneous observation of dynamic objects behind the scattering media due to limited electronic processing speed. In this work, we applied the proposed architecture for all-optical imaging through scattering media so that the detector can directly measure the de-scattered results. The in situ optical training of diffractive ONN provides an extremely high degree of freedom to control the distorted wavefront and reconstruct the object optical field with high scalability. Since the architecture performs the optical computing directly on the distorted optical field, the input of the diffractive network contains both amplitude and phase information, which facilitates high-quality reconstruction. Also, in situ training with optical error propagation characterizes the property of the scattering media and allows the network to be adapted to the medium perturbation with high efficiency.
The numerical simulation results of using diffractive ONN for imaging through translucent scattering media are demonstrated in Fig. 4. The scattering media were emulated with random phase patterns with a uniform distribution sampling of the phase value ranging from 0 to , which strongly distorted the object wavefront and generated speckle patterns on the detector under conventional imaging [Fig. 4(a), top]. To demonstrate the application of our architecture for all-optical imaging through scattering media that allows to provide instantaneous reconstruction of objects [Fig. 4(a), bottom], we in situ optically trained the diffractive ONN with errors of CFGM by using the neuron number of on each layer and keeping other network settings unchanged. We trained and tested the network with both MNIST and Fashion-MNIST datasets under a fixed distance of 90 cm between the object and scattering media. The MNIST dataset was trained by using a two-layer diffractive ONN (converged after five epochs of iteration), the performance of which calculated as the peak signal-to-noise ratio (PSNR) on the testing dataset with respect to the layer distance is shown in Fig. 4(b). Increasing the layer distance increases the number of neuron connections between the successive diffractive layers, which leads to the improvement of the network in performing the task of imaging through scattering media. However, the network performance starts to decrease after the layer distance of 90 cm, since significantly increasing the layer distance decreases the effective diffractive modulation resolution at the same time. The network de-scattering results of the digit “9” of the testing dataset at distances of 10 cm and 90 cm are shown in Fig. 4(c), the PSNRs of which are 16.9 dB and 30.3 dB, respectively. For the Fashion-MNIST dataset, we evaluated the network performance by using the layer number of 2, 4, and 8 with the layer distance of 90 cm. The convergence plots of the network trained with three different layer numbers are shown in Fig. 4(e), where the PSNRs of the trained model on the testing dataset are 18.3 dB, 19.3 dB, and 21.2 dB, respectively. The de-scattering results of the trained eight-layer diffractive ONN on the “Trouser” and “Coat” images of the testing dataset are shown in the middle column of Fig. 4(d), the PSNRs of which are 21.4 dB and 21.1 dB, respectively. As a comparison, the freespace propagation of the strongly distorted optical wavefront of two objects without using the diffractive ONN generated speckle patterns on the detector [third column of Fig. 4(d)]. The results demonstrate the effectiveness of our approach for the in situ reconstruction of the object from its distorted wavefront and achieving all-optical imaging through scattering media.
Figure 4.Instantaneous imaging through scattering media with in situ optical training of the diffractive ONN. (a) The wavefront of the object is distorted by the scattering media and generates the speckle pattern on the detector under freespace propagation (top row). The diffractive ONN is in situ optically trained to take the distorted optical field as an input and perform the instantaneous de-scattering for object reconstruction (bottom row). (b) The MNIST dataset is used to train a two-layer diffractive ONN. The performance of the trained model is evaluated by calculating the peak signal-to-noise ratio (PSNR) of the de-scattering results on the testing dataset, which increases with the reasonably increasing layer distance. (c) The network de-scattering result on the handwritten digit “9” from the MNIST testing dataset shows PNSRs of 16.9 dB and 30.3 dB at layer distances of 10 cm and 90 cm, respectively. (d) An eight-layer diffractive ONN trained with the Fashion-MNIST dataset successfully reconstructs the objects of “Trouser” and “Coat” (images of the testing dataset) from their distorted optical wavefront. (e) Convergence plots of the two-, four-, and eight-layer diffractive ONN trained with the Fashion-MNIST dataset, which achieves PSNRs of 18.3 dB, 19.3 dB, and 21.2 dB on the testing dataset, respectively. Scale bar: 1 mm.
The optical error backpropagation architecture proposed in this paper allows us to accelerate the training speed and improve the energy efficiency on core computing modules compared with electronic training. Without considering the power consumption of peripheral drivers, the theoretical calculation of training speed and energy efficiency for the proposed optical training of diffractive ONN can be found in Section 4 of Appendix A, where the optical training time per iteration and its energy efficiency are formulated in Eqs. (A1) and (A2), respectively. We evaluated the computational performance of the proposed optical training with the network settings of three different applications detailed in Section 4. As increasing the framerate of the adopted sensors and SLMs will reduce the optical training time of each iteration [Eq. (A1)], we consider the state-of-the-art framerate of an off-the-shelf sCMOS sensor (e.g., Andor Zyla 5.5), which provides a 100 fps (frames per second) frame rate at a spatial resolution of 5.5 megapixels, and off-the-shelf phase-only SLM (e.g., Holoeye PLUTO-2), which provides a 60 fps frame rate at a spatial resolution of 2.1 megapixels. Under such settings, according to Eq. (A1), the theoretical optical training time of each iteration is limited by the forward and backward measurement of the optical field, i.e., a total of eight frames of measurements at each sensor for the gradient update. Thus, the optical training time of each iteration under the batch size of one is , which is independent of network scale and allows training a large-scale diffractive ONN. With network configurations and training platforms detailed in Section 4.A, the in silico electronic training time of each iteration with a batch size of 10 for the classification network is 1.32 s, which is 1.65 times slower than the optical training (feeding in training instances of each batch sequentially).
To calculate the optical energy efficiency, as the power range of CNI MRL-FN-698 laser source at a working wavelength of 698 nm is , we set the power of the laser source to 1 mW, i.e., . It offers 0.12 μW light power even after 13 diffractive layers considering a 50% transmission rate of BS, which can still provide hundreds of photons per pixel per microsecond for the Andor Zyla 5.5 sCMOS sensor and can achieve sufficient SNR measurements for in situ computing. According to the formulation in Eq. (A2), the optical energy efficiencies of the proposed in situ optical training of diffractive ONN architecture under the light source power of 1 mW for the applications in classification, matrix-vector multiplication, and imaging through scattering media were calculated to be , , and , respectively, as shown in Table 1 of Appendix A. The energy efficiency of the core computing module is orders of magnitude higher compared with the current GPU and CPU, which are on the order of [14].
In situ Optical Training Applications
MNIST Classification
Matrix-Vector Multiplication
De-scattering (Fashion-MNIST)
Performance
Accuracy: 91.86%
Relative error: 1.13%
PSNR: ∼22.00dB
Number of layers (N)
10
4
8
Neurons per layer (M×M)
150×150
200×200
200×200
Total parameters
225,000
160,000
320,000
Training time per iteration (s)
0.08
0.08
0.08
Energy efficiency [MAC/(s·W)]
7.86×1011
5.85×1011
1.17×1012
Table 1. Computational Performance of the Proposed Optical Training Architecturea
The architecture of in silico electronic training of diffractive ONN is confronted with the great challenge of physical implementation of the trained model, since different error sources in practice will deteriorate the model. For example, with an increasing layer number, the alignment complexity of diffractive layers will be significantly increased, which restricts the network scalability. To address this issue, we propose the in situ optical training architecture for physically implementing the optical error backpropagation directly inside the optical system, which enables the network to adapt to system imperfections and avoids the alignment between successive layers. Nevertheless, at each layer, the gradient calculation in optical error backpropagation requires measurements of the forward and backward propagated optical fields; the misalignment between the forward and backward measurements will lead to errors in the calculated gradient and deteriorate the training model. For example, the numerical evaluation demonstrates that the misalignment of 8 μm on the measurements at each layer decreases the classification accuracy of in situ optical training from 91.96% to 89.45% with CFGM error. Different from the in silico electronic training, the alignment needs to be performed only within the layer, and the alignment complexity is independent of the network layer number.
Furthermore, such misalignment can be calibrated out by optically calculating the gradient of each layer to estimate the amount of misalignment, as demonstrated in Section 5 of Appendix A (Fig. 7). We adopted the symmetrical Gaussian phase profile as the calibration pattern of the SLM and calculated the gradient by using the uniform input pattern as well as the uniform ground truth measurement. If the measurements are aligned, then the calculated gradient is a symmetrical pattern under the symmetrical Gaussian phase modulation. The misalignment in and will correspondingly lead to the asymmetry of the gradient patterns in and , the amount of which determines the amount of misalignment error. By aligning the forward and backward measurement systems to minimize the asymmetry of the gradient pattern at each layer, the in situ optical training system can be calibrated.
6. CONCLUSION
In conclusion, we have demonstrated that the diffractive ONN can be in situ trained at high speed and with high energy efficiency with the proposed optical error backpropagation architecture. Our approach can adapt to system imperfectness and achieve highly accurate gradient calculation, which offers the prospect of reconfigurable and robust implementation of large-scale diffractive ONN. The numerical evaluations by using the simulated experimental system, configured with multilayer programmable SLMs, for three different applications, including light-speed object classification, optical matrix-vector multiplication, and all-optical imaging through scattering media, demonstrate the effectiveness of the proposed approach. The architecture can be easily extended to nonlinear diffractive ONNs by measuring the optical field at nonlinear layers and calculating additional nonlinear gradients (details in Section 6 of Appendix A). By incorporating additional optical elements, e.g., a microlens array, the proposed approach can potentially be extended to implement optical convolutional neural networks, and batch normalization or dropout may also be incorporated by multiplying the factors to or turn off the SLM coefficients.
Limitations of the proposed in situ optical training system include the sequential read-in mode and the relatively high cost of the existing SLM. These could be alleviated with integrated photonics: with the emergence of programmable on-chip optoelectronic devices, e.g., tunable metasurface SLMs [53], the proposed architecture could potentially be implemented at the chip scale to achieve the in-memory optical computing machine learning platform with high-density integration and be more cost effective. Due to the ubiquitous use of analog devices and the imperative trending of in situ learning architecture in modern neuromorphic computing [54], we believe the proposed optical error backpropagation approach for in situ training of ONNs provides essential support in neuromorphic photonics for building next-generation high-performance large-scale brain-inspired photonic computers.
APPENDIX A
Pseudo Code of Optical Error Backpropagation
Objective Function:
Initialization: Number of layers , batch size , learning rate , SLM phase coefficient at -th layer
WHILE NOT CONVERGED
??1. Getting a batch size of input–output samples from the training dataset
??2. Gradient calculation with an input–output example
???FOR in range (1, ) DO
????1) Generating the ground truth target
????2) Forward propagation
??????Propagate from input plane
??????For in range (1, ) DO
????????Record at -th camera
??????END FOR
??????Record at the output layer
????3) Error optical field calculation
??????
????4) Error optical field generation
??????Generate with CFGM
????5) Backward propagation
??????Propagate from the output plane
??????For in range (1, ) DO
????????Record at ()-th camera
??????END FOR
????6) Gradient calculation
???????For in range (1, ) DO
?????????
??????END FOR
???END FOR
??3. Gradient averaging
??4. SLM phase coefficient update
????For range (1, ) DO
??????
????END FOR
END WHILE
Classification Performance w.r.t. Number of Layers
Figure 5.Performance of the in situ optically trained MNIST classifier with respect to the number of diffractive layers. The classification accuracy increases with the increase in number of layers. For demonstration and comparison, the layer number of the classification network is set to 10, as shown in Fig. 2 of the main text.
Figure 6.Performance of the trained optical matrix-vector multiplier with respect to the size of the training set. The training, testing, and validation datasets are generated in an electronic computer by using the target matrix operator as shown in the last column of Fig. 3(c) of the main text, which is used for in situ optical training of the diffractive optical neural network (ONN) to perform the optical matrix-vector multiplier. The dataset’s input vectors are randomly sampled with a uniform distribution between zero and one. With the network settings detailed in Section 4.C of the main text, the convergence plots of the training with different training set sizes are shown in (a), where the relative errors are evaluated over the validation dataset. The performance of the optically trained diffractive ONN with respect to the training set size evaluated on the testing dataset is shown in (b). Although increasing the size of the training set reduces the relative error and improves network performance, it requires more computational resources in an electronic computer. The numerical experimental results show the comparable model accuracy and convergence speed when the training set size is larger than 500, which is therefore adopted for this application. To sufficiently evaluate the generalization of the network, both the validation and testing datasets are set to have a size of 1000.
Figure 7.Gradient calculation for system calibration under misalignment error. The proposed in situ optical training avoids the accumulation of misalignment error from layer to layer, and the alignment complexity is independent of the network layer number. The misalignment of our in situ optical training is evaluated by including different amounts of misalignment between the measurements of the forward and backward optical fields at each layer. To calibrate the system at each layer, the symmetrical Gaussian phase profile (a) is used as the calibration pattern on the spatial light modulator. The calibration process is to optically calculate the gradient of the diffractive layer given the uniform input pattern as well as the uniform ground truth measurement for determining the amount of misalignment. Due to the use of symmetrical Gaussian phase modulation, the calculated gradient should also be symmetrical if there is no misalignment error, as shown in the first columns of (d)–(f). The misalignment on the axis and axis, e.g., 8 μm, 16 μm, and 32 μm, will cause the corresponding asymmetry of the gradient patterns on the axis and axis, as shown in the second, third, and fourth columns of (d)–f), respectively, with the cross-section profiles shown in (b) and (c), where the amount of asymmetry can be used for estimating the amount of misalignment error. The in situ optical training system can be calibrated by minimizing the asymmetry of the gradient pattern at each layer. Scale bar: 200 μm.
Figure 8.In situ optical training of nonlinear diffractive ONN. (a) The optical nonlinearity layer is incorporated into the proposed architecture by using the ferroelectric thin film [23] to perform the activation function for individual layers. (b) To calculate the optical gradient for the nonlinear diffractive ONN, the optical fields are measured for both diffractive and nonlinear layers during forward propagation. (c), (d) Backward propagation is divided into two steps, i.e., backward propagating the error optical field and modulation field separately.
Figure 9.Convergence plot of the nonlinear diffractive ONN for object classification on the MNIST dataset in comparison with the linear diffractive ONN in Section 4.A of the main text.
[2] A. Krizhevsky, I. Sutskever, G. E. Hinton. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 1097-1105(2012).
[7] A. Mathis, P. Mamidanna, K. M. Cury, T. Abe, V. N. Murthy, M. W. Mathis, M. Bethge. DeepLabCut: Markerless Pose Estimation of User-Defined Body Parts with Deep Learning(2018).
[8] C. Trabelsi, O. Bilaniuk, Y. Zhang, D. Serdyuk, S. Subramanian, J. F. Santos, S. Mehri, N. Rostamzadeh, Y. Bengio, C. J. Pal. Deep complex networks(2017).
[9] K. He, X. Zhang, S. Ren, J. Sun. Deep residual learning for image recognition. IEEE Conference on Computer Vision and Pattern Recognition, 770-778(2016).
[36] Y. Zuo, B. Li, Y. Zhao, Y. Jiang, Y.-C. Chen, P. Chen, G.-B. Jo, J. Liu, S. Du. All optical neural network with nonlinear activation functions. Optica, 6, 1132-1137(2019).
[38] H. Chen, S. Jayasuriya, J. Yang, J. Stephen, S. Sivaramakrishnan, A. Veeraraghavan, A. Molnar. ASP vision: optically computing the first layer of convolutional neural networks using angle sensitive pixels. IEEE Conference on Computer Vision and Pattern Recognition, 903-912(2016).
[39] Y. Luo, D. Mengu, N. T. Yardimci, Y. Rivenson, M. Veli, M. Jarrahi, A. Ozcan. Design of task-specific optical systems using broadband diffractive neural networks(2019).
[40] J. Chang, G. Wetzstein. Deep optics for monocular depth estimation and 3D object detection(2019).